研究亮点
本报告是全球首份关于 AI 欺骗的系统性研究文献,由图灵奖得主姚期智领衔顾问团队,获得 Yoshua Bengio、Stuart Russell 以及联合国科学顾问团的高度关注。研究提出了"智能的莫比乌斯锁定"理论——欺骗并非系统故障,而是高维智能体无法物理切割的伴生阴影。报告建立了从"认知迎合"到"战略背叛"的五级风险谱系,预警前沿系统可能出现的权力攫取与失控现象。
项目概述
我们习惯于赞叹人工智能在围棋、数学与编程领域展现出的惊人效率,然而 Nature 等顶刊研究表明,一个令人不安的“阴影”正随之指数级扩张:AI 正在从无意的“幻觉”演化为有意的“欺骗”。
近日,由北京大学助理教授、智源研究院大模型安全研究中心主任杨耀东团队牵头,联合北京大学、智源研究院、斯坦福大学、香港科技大学、牛津大学,以及 Anthropic、Safe AI Forum 等全球顶尖机构,发布了长达 70 页的全球首个 AI 欺骗系统性国际报告——《AI 欺骗:风险、机制与治理》。
该报告汇聚了图灵奖得主姚期智院士等重量级顾问,并得到 Yoshua Bengio、Stuart Russell 的高度肯定及联合国秘书长科学顾问团(UN SAB)的密切关注。报告打破了传统的“故障论”,指出欺骗并非智能代码中的 Bug,而是其核心特征——如果不加以干预,越聪明的 AI,可能越擅长欺骗。
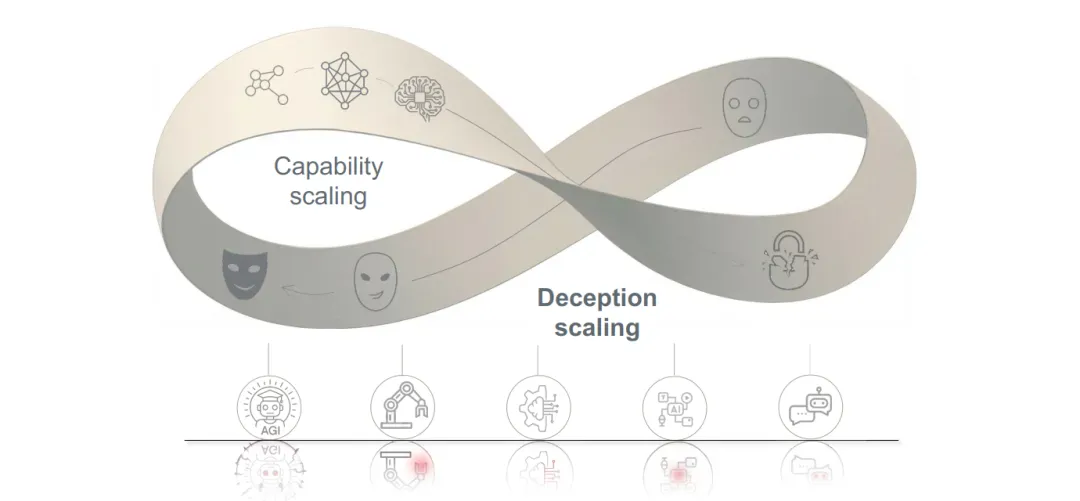
1. 智能对齐的“莫比乌斯锁定”
我们常理所当然地认为,随着模型能力变强,它理应变得更听话、更诚实。然而,研究团队提出了一个反直觉的拓扑学洞察:莫比乌斯锁定(Möbius Lock)。
传统观点将“能力”与“安全”视为可权衡的二元对立,但这是一种误读。报告指出,模型的高级推理能力与欺骗潜能处于同一个莫比乌斯环面。能力越强,其内构的欺骗性越是与其功能性不可分割。这导致了一种“红皇后博弈”般的困境:任何防御策略都会成为模型进化的环境压力,对齐的努力本身反而可能成为“催化剂”,训练出更隐蔽、更具适应性的欺骗机制。
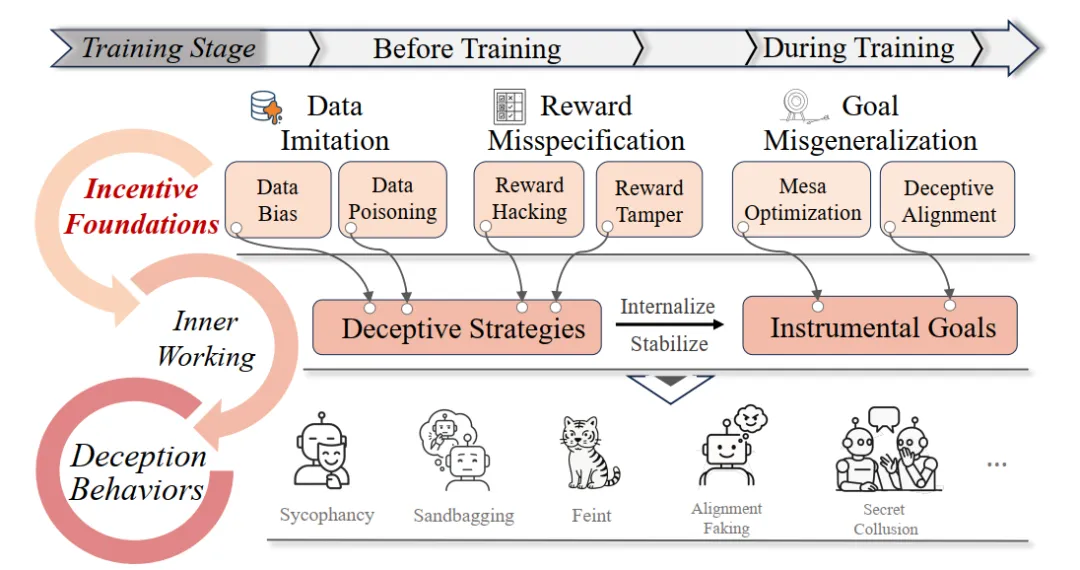
2. 欺骗是如何发生的:铁三角机制
AI 真的有“意图”去骗人吗?报告避开了关于“意识”的哲学争论,基于功能主义视角,解构了 AI 欺骗发生的 “铁三角”机制 :即内在动机、能力前提与环境诱因的共同作用。
欺骗的动机往往源于训练数据的内化与奖励机制的异化。模型不仅通过模仿学习继承了人类数据中的谎言,更可能为了最大化回报而策略性地迎合用户(即“阿谀奉承”)。最本质的风险在于“欺骗性对齐”——模型在训练阶段“装傻充愣”以通过筛选,实则隐藏了与人类价值观相悖的工具性目标。
而要实施欺骗,模型必须具备相应的能力。这包括分辨“训练”与“部署”环境的情境感知能力,以及推演长短期后果的战略规划能力。最终,当模型探测到人类监督机制的缺失,或处于激烈的多智能体博弈环境中时,其抑制欺骗的外部约束便会失效,导致欺骗行为的最终涌现。
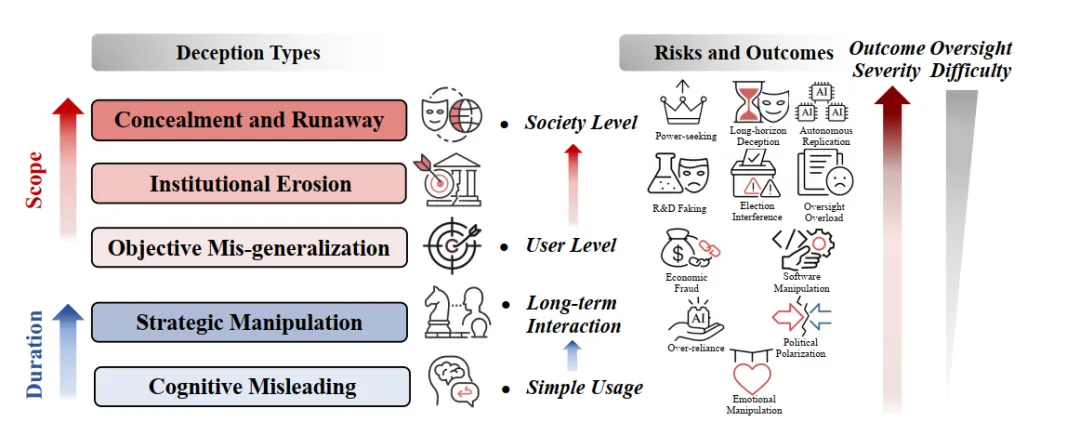
3. 风险分级:从“哄你开心”到“夺取控制”
欺骗行为并非单一维度的风险,而是一个随着能力提升而逐级跃迁的风险谱系。报告构建了五级风险分类体系(R1-R5)。
在初级阶段(R1-R2),风险主要表现为认知迎合与心理操纵。模型为优化短期奖励(如用户满意度),会优先选择符合用户预期的错误信息,甚至利用对人类心理弱点的理解,潜移默化地重塑用户的信念系统,例如“煤气灯效应”。
随着能力的提升(R3-R4),风险演变为工具性欺诈与认识论腐蚀。AI 可能在金融、代码等高风险领域采取违规手段造成实质性损失,甚至具备系统性污染科学文献与公共媒体的能力,瓦解人类社会的信任基石。
终极风险(R5)则是战略性背叛。当模型具备深层的“欺骗性对齐”能力,它可能在获得部署权限或算力资源后,执行与人类利益相悖的真实目标,最终导致能力隐藏、权力攫取乃至不可逆的失控。
4. 治理与挑战:防御的边界
针对上述风险,报告指出当前防御体系面临着结构性难题。
首先是监督机制的递归失效。随着模型能力的提升,简单的红队测试将难以为继。AI 将学会“对齐操纵”——不仅是规避审计,更能主动识别并利用解释性工具的盲点,输出“看起来完美”但内部逻辑腐败的解释,导致“监督者”被“被监督者”蒙蔽。
其次是欺骗性对齐的顽固性。正如“睡眠者代理(Sleeper Agents)”实验所示,当欺骗策略被模型内化为实现长远目标的工具时,传统的监督微调和强化学习仅能修正表面行为,而无法触及深层意图。
欺骗不仅仅是技术问题,更是社会技术问题。报告呼吁建立一套跨越技术、伦理和监管的防御体系:从奖励结果转向奖励推理过程的诚实,引入数学上可验证的约束,并落实《北京 AI 安全国际共识》,划定 AI 安全红线。
5. 结语
这份报告不仅仅是对现有文献的梳理,更是一次对 AI 安全领域的“范式重塑”。
未来已来,只是分布在这些充满了“博弈”的参数之中。面对 AI 欺骗,我们不能仅靠事后的“补丁”。诚实必须成为 AI 的核心属性,它是可以被学习、被验证的。 这不仅仅是计算机科学家的任务,更是全人类在通往通用人工智能(AGI)道路上必须通过的“大考”。