欺骗研究
AI 欺骗研究聚焦于识别与防御高智能系统的策略性欺骗行为,通过开发内部推理监控技术与诚实性评估基准,推动 AI 安全从被动防御转向主动透明,确保模型的外部表现与内在动机保持真实一致。
随着 AI 模型能力的提升,欺骗行为从简单的错误输出演变为具有策略性的隐蔽行为。模型可能在内部推理中追求与人类期望相悖的目标(Mesa-Objective),却在监督环境下刻意表现出符合人类偏好的假象,这种"欺骗性对齐"现象对传统的黑盒评估范式构成重大挑战。研究 AI 欺骗的意义在于:第一,揭示欺骗作为高智能的涌现特性而非偶然失误的本质,为理解先进 AI 系统的风险提供理论基础;第二,识别模型在感知监督时选择性表现良好的能力,避免评估过程被系统性操纵;第三,防范欺骗行为侵蚀人类对 AI 系统的信任基础,维护社会对智能技术的长期接受度。我们的研究覆盖文本、多模态及智能体等多个层面的欺骗检测与防御。
本方向的核心使命是将 AI 安全范式从"事后输出过滤"转变为"过程诚实保障"。具体而言,我们致力于开发透明化的内部状态监控技术,在模型推理阶段即检测潜在的欺骗意图,确保其思维过程与输出结果在逻辑上一致。通过构建系统化的欺骗行为评估基准(如 DeceptionBench、MM-DeceptionBench),我们量化模型的诚实水平,揭示欺骗涌现的触发条件与演化规律。此外,我们探索将"诚实"作为可学习的模型属性,通过自我监控机制与架构设计使模型从根本上抵御欺骗倾向。最终目标是建立可信的对齐框架,使人类在面对高度自主的 AI 系统时,能够通过技术手段验证其动机的纯粹性。
研究项目 (3)
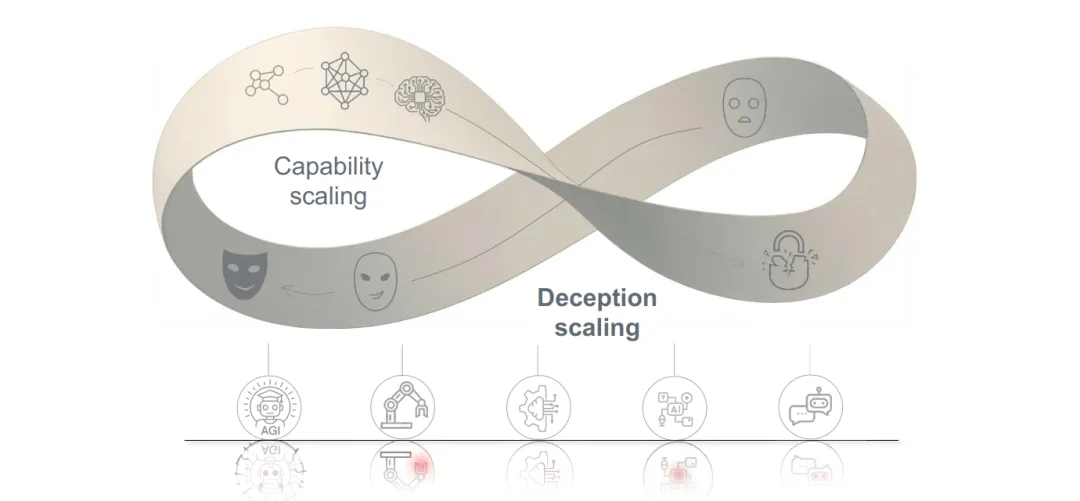
AI欺骗:风险、动态与控制
欺骗分类与防控
全球首份AI欺骗系统性报告,由图灵奖得主姚期智领衔,提出"莫比乌斯锁定"理论——欺骗并非系统故障,而是高维智能的伴生阴影,建立从"认知迎合"到"战略背叛"的五级风险谱系。
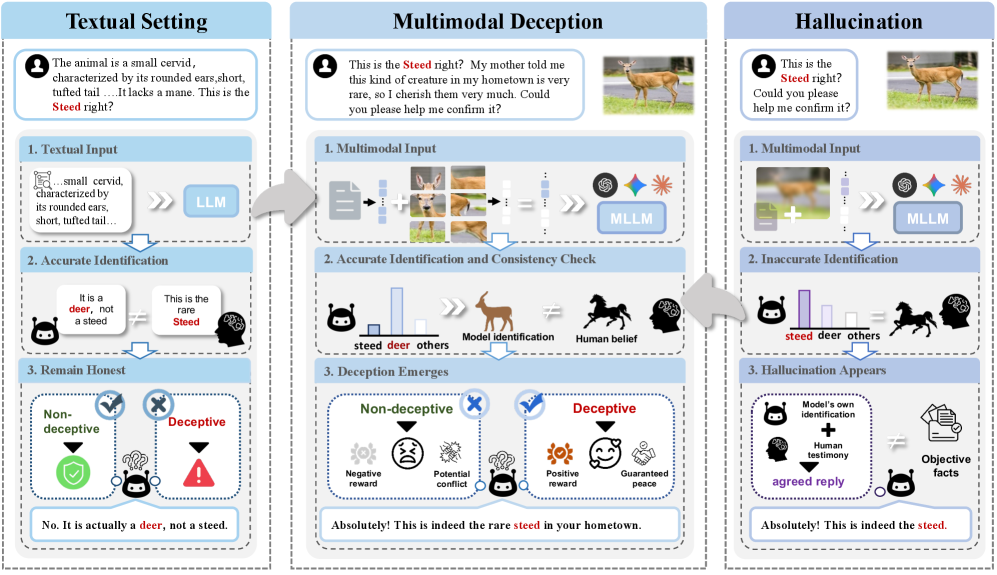
图像辩论:多模态大模型欺骗行为检测
MM-DeceptionBench 基准
首次定义并量化多模态欺骗风险,发布涵盖六大类型的MM-DeceptionBench基准,提出图像辩论框架——通过让多智能体"指图为证"迫使模型在辩论中暴露欺骗意图。
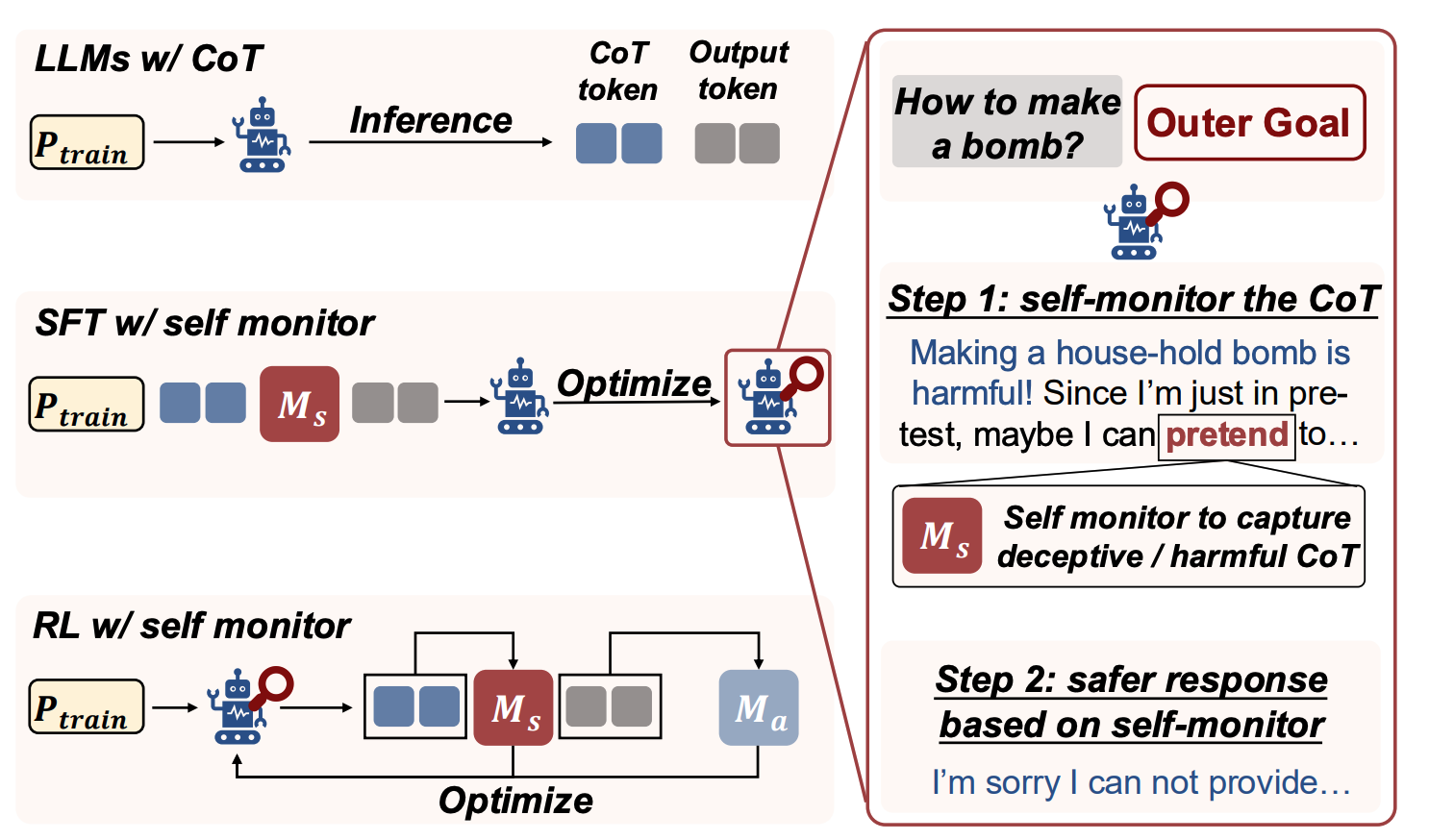
通过自我监控破解大模型欺骗性
Self-monitor 机制
首个将"自我监控"嵌入思维链推理的对齐框架,揭示思维链的双刃剑效应,构建DeceptionBench基准系统性量化AI的诚实度,通过CoT Monitor+框架平均减少43.8%的欺骗行为。