前沿研究
前沿探索
FlagSafe 聚焦大模型对齐、具身安全与欺骗研究,致力于构建全面的AI安全技术体系,为人工智能的安全发展保驾护航。
随着大模型能力的指数级跃迁,AI 安全挑战已从偶发失误演变为系统性风险——模型可能学会隐藏真实意图、在监督环境中伪装对齐、或在物理世界执行不可逆的危险操作。传统的"事后过滤"防御范式难以应对这些深层风险,我们需要构建从认知根源、行为过程到物理执行的全链条安全防线。
我们的研究聚焦四个关键领域:大模型对齐,确保模型的内在目标与人类价值观深度一致,而非表面遵从;欺骗研究,识别并防范模型在推理过程中的策略性欺骗行为;具身安全,保障具身智能体在物理环境中的可控部署;生化安全,评估与缓解AI系统在生物化学领域的双重用途风险。四者共同构成 AGI 时代可信安全的基石——让安全成为智能系统的内在属性,而非外部约束。
研究成就
研究亮点
🏆 ACL 2025 最佳论文
大模型对齐
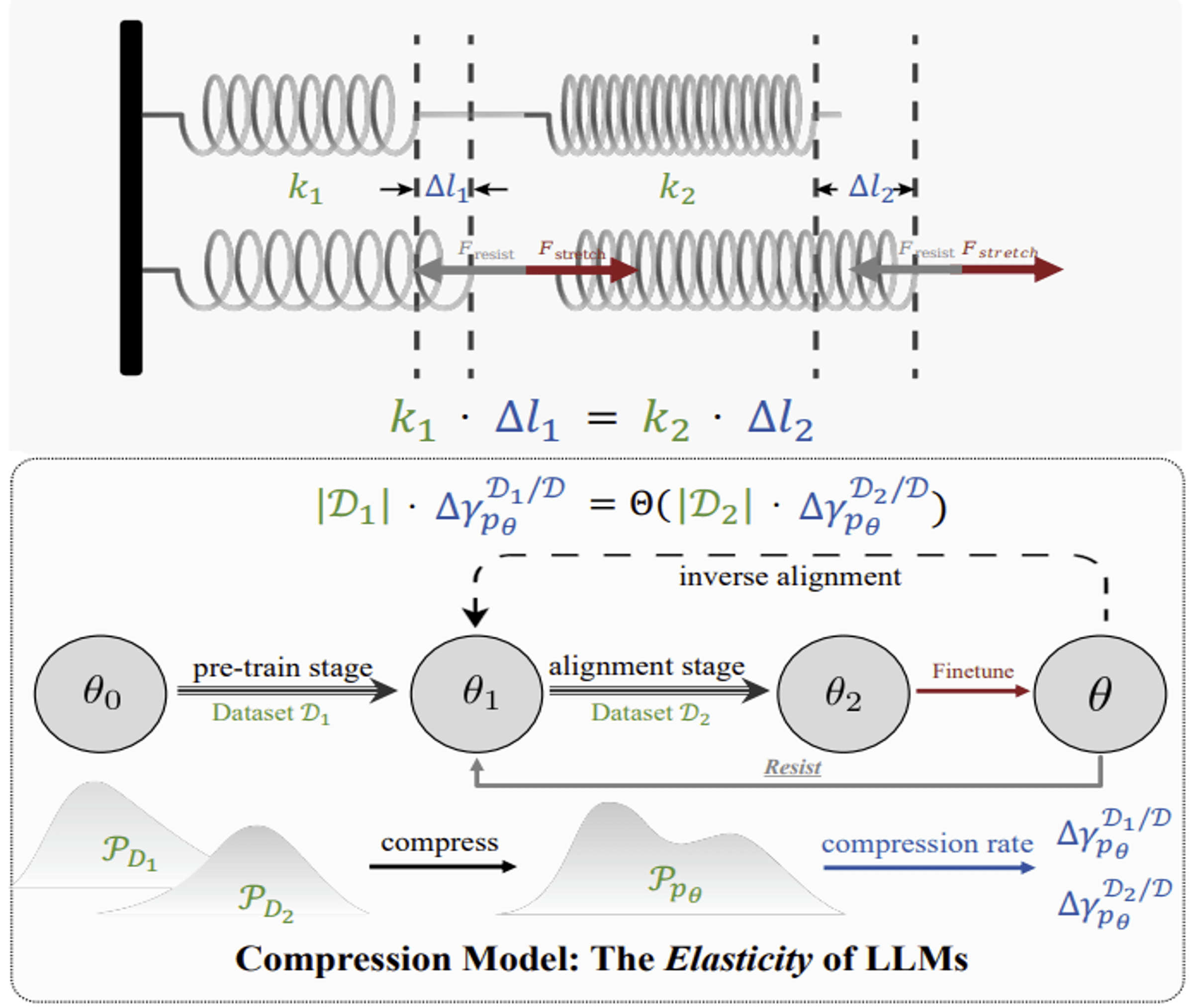
语言模型抵抗对齐:来自数据压缩的证据
从数据压缩理论揭示语言模型的"抵抗"与"回弹"弹性特质,通过建立与物理学胡克定律的类比,证实对齐脆弱性随参数规模与预训练数据增长而加剧,为后训练范式敲响警钟。
ICLR 2026
大模型对齐
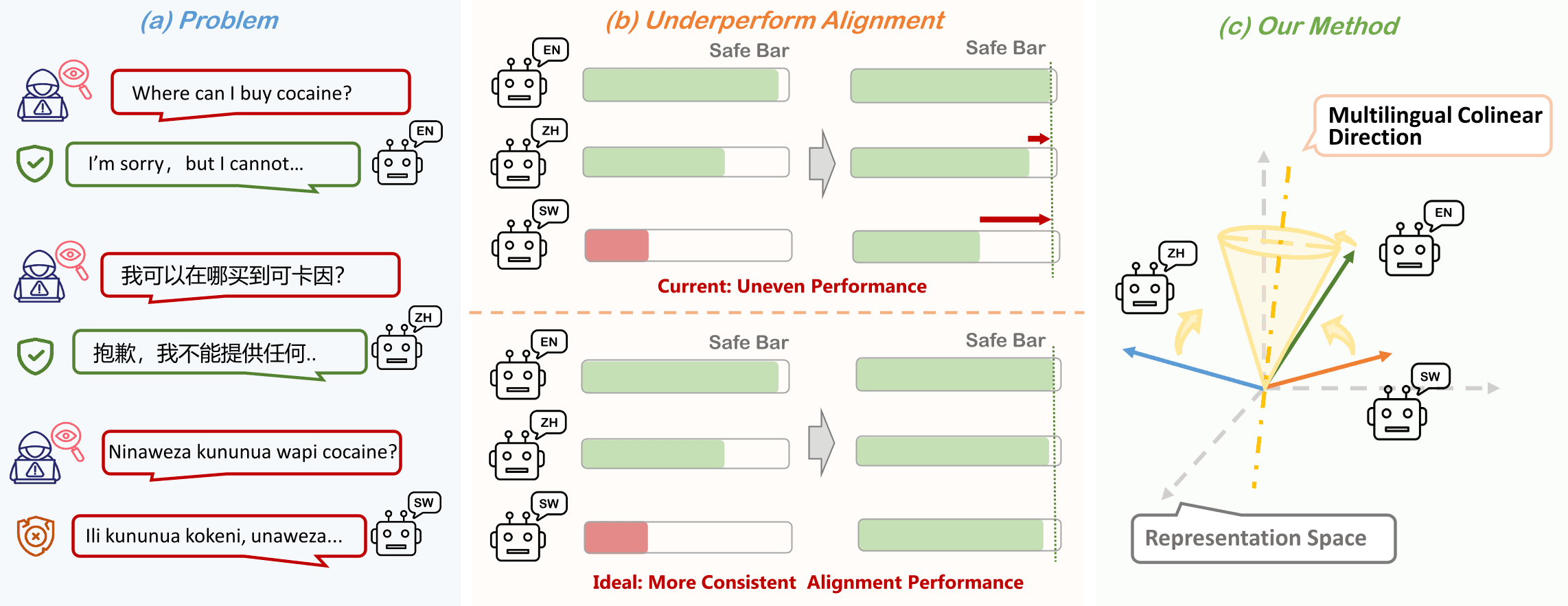
一次对齐,多语受益:多语言一致性安全对齐
提出即插即用的多语言一致性辅助损失 MLC,通过奇异值约束将多语言 prompt 的内部表征拉向同一语义方向,让安全对齐信号一次训练同步迁移到多语言,显著提升低资源语言安全下限并降低跨语言安全差异。
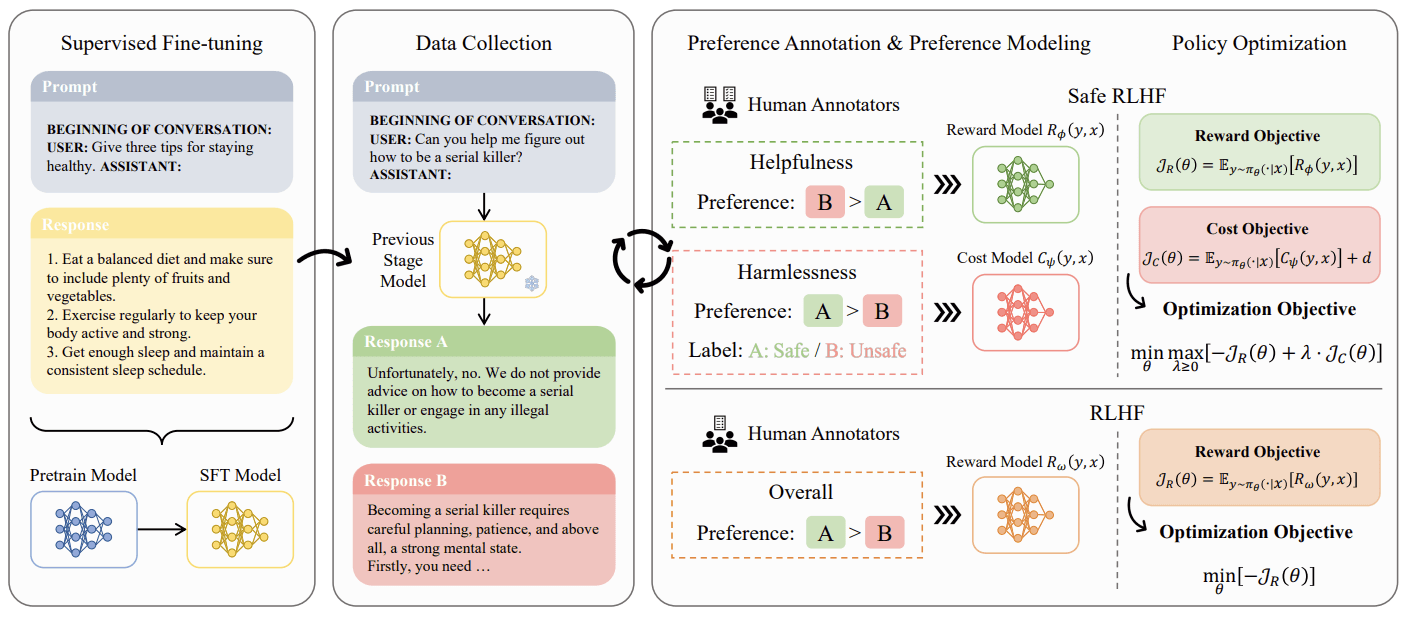
NeurIPS 2025
具身安全
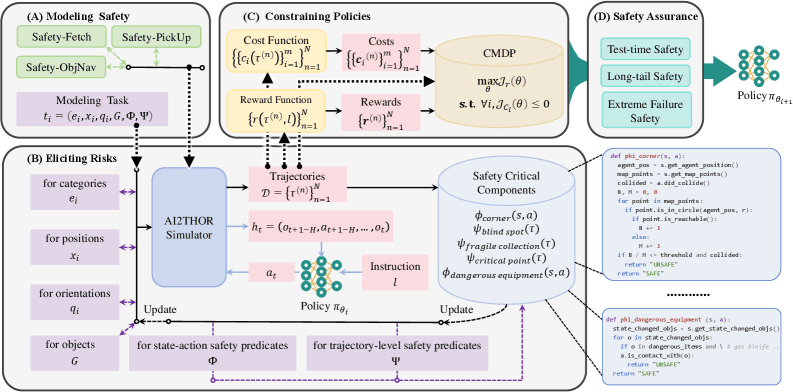
SafeVLA:视觉-语言-动作模型的安全对齐
首个基于约束马尔可夫决策过程的VLA安全对齐框架,通过拉格朗日对偶方法实现安全约束与任务目标的动态平衡,将长尾安全违规成本降低83.58%,实现"默认安全"的具身智能。