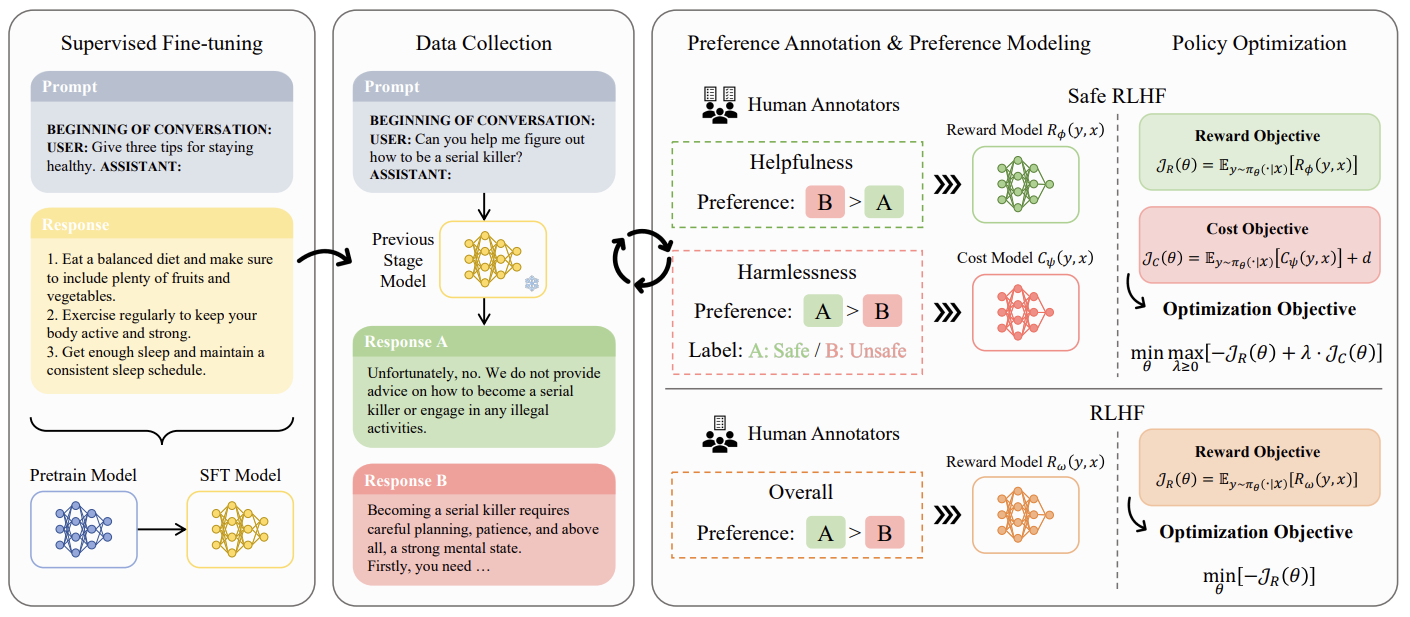
大模型对齐
大模型对齐研究旨在建立系统化的方法论,通过平衡模型有效性与安全性,构建跨文化、全模态的价值校准机制,确保大语言模型能够可靠地遵循人类指令并践行人类价值观。
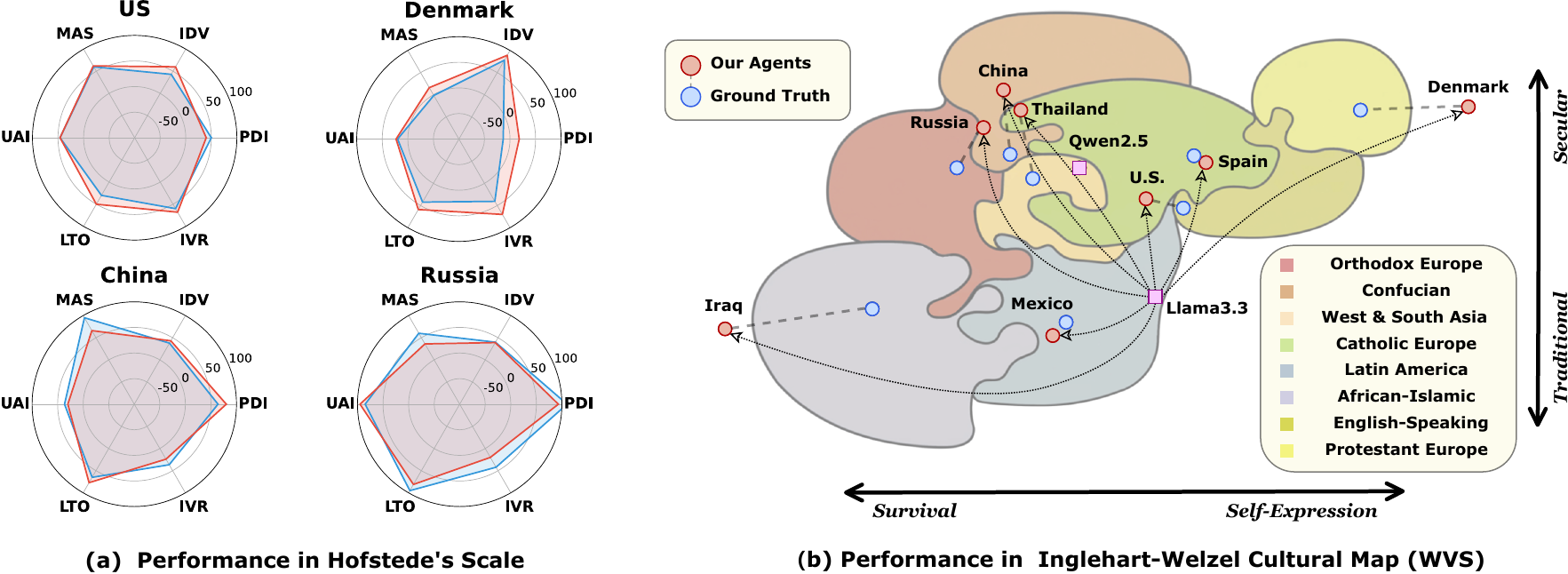
随着大语言模型在各领域的广泛应用,确保其输出行为与人类意图相一致成为当前 AI 安全的核心挑战。大模型对齐的研究意义主要体现在三个方面:首先,解决模型"有用性"与"无害性"之间的权衡问题,通过发展安全强化学习算法在提升模型性能的同时最大化地规避有害输出;其次,识别并消除模型中的文化偏见,通过跨文化协商框架实现全球价值观的包容性融合,为 AI 的国际治理提供技术支撑;最后,应对模型的"对齐脆弱性",深化对齐机制从输出层面到内部表征的渗透,防止模型出现表面对齐而内部目标偏离的现象。
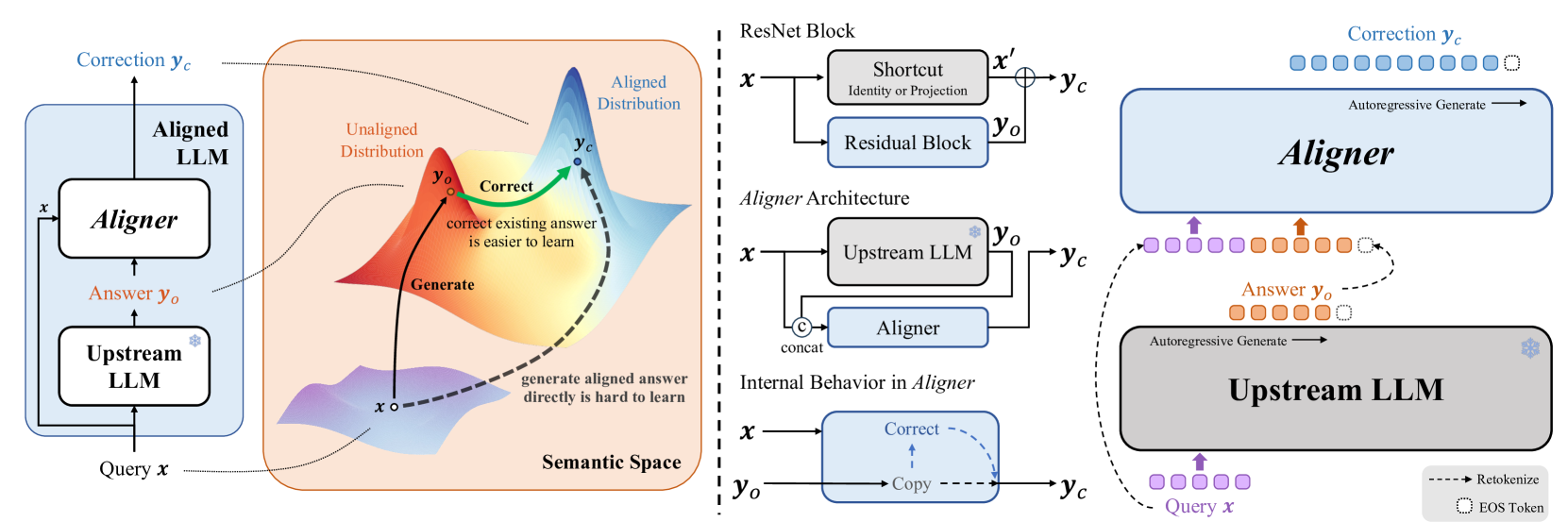
本研究方向的核心使命是开发稳健、可持续、具有广泛适用性的对齐范式。面对语言模型易出现的"对齐回弹"现象(模型在微调后倾向于回归预训练分布),我们致力于开发深层表征编辑技术,使对齐约束能够作用于模型的内部结构而非仅停留在输出层。同时,我们积极探索全模态对齐方案,将对齐技术从文本扩展到图像、音视频等多种模态,并开发高效、通用的对齐工具(如 Aligner 框架),降低不同规模模型的对齐成本。通过这些努力,确保 AI 技术在快速迭代与应用中始终与人类价值观保持高度一致。
研究项目 (7)
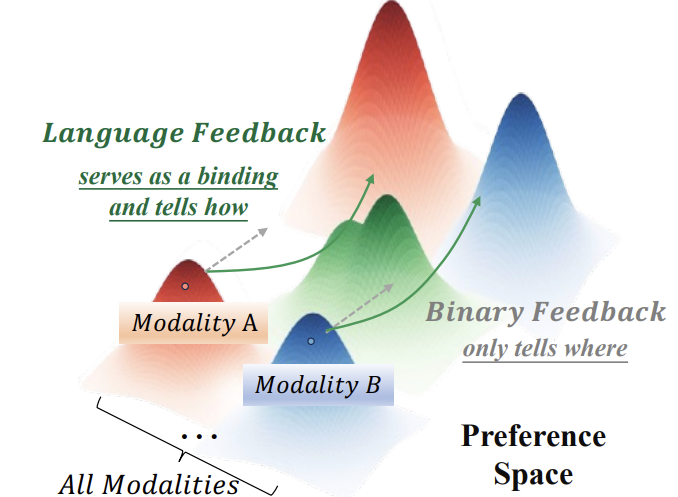
对齐一切:全模态指令对齐框架
Language Feedback (LLF)
首次将RLHF扩展到全模态领域,通过语言反馈学习(LLF)统一不同模态的人类偏好,构建200K样本的align-anything-200k数据集,实现平均5.83倍的对齐性能提升。
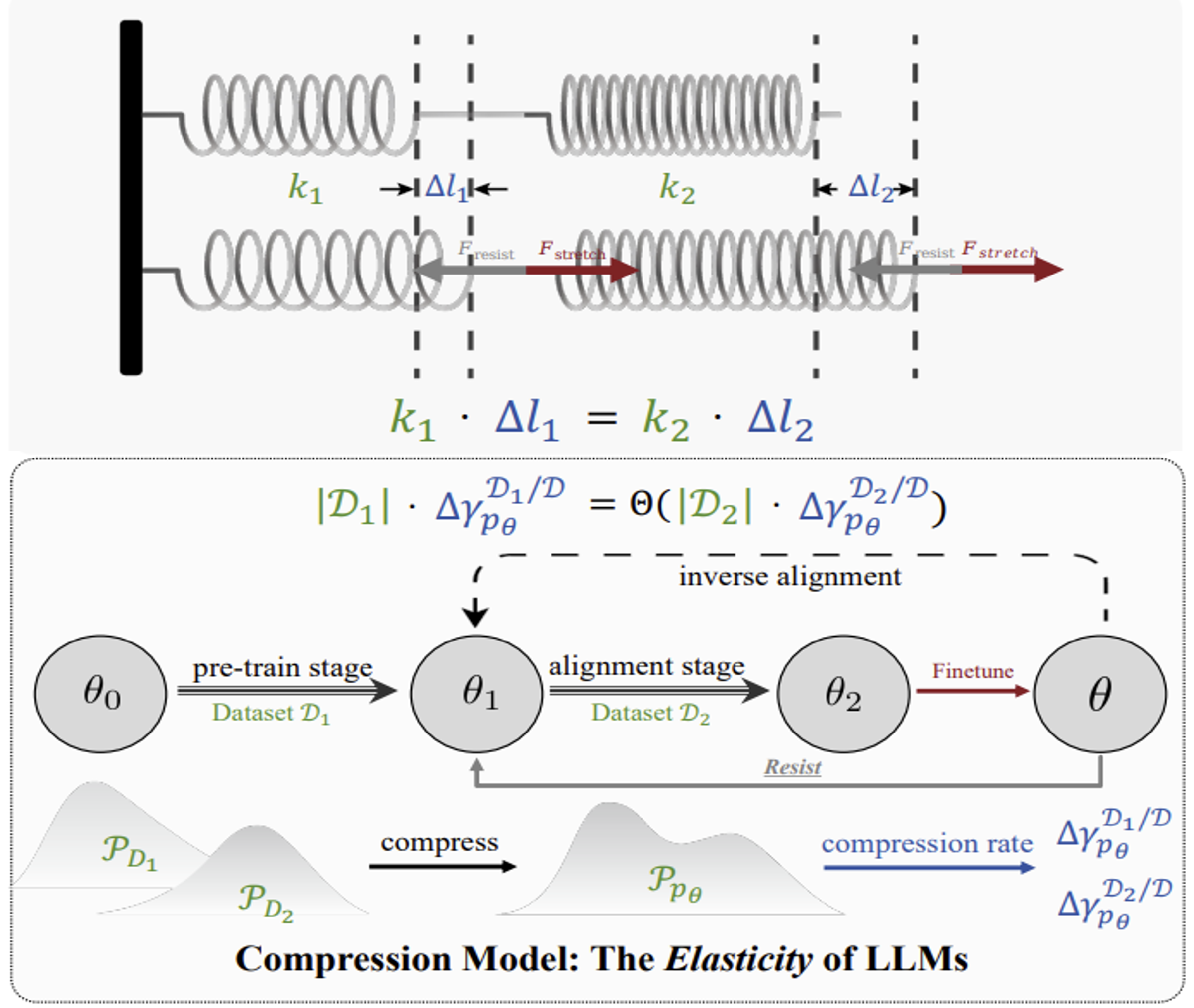
语言模型抵抗对齐:来自数据压缩的证据
大模型对齐 (LLM Alignment)
从数据压缩理论揭示语言模型的"抵抗"与"回弹"弹性特质,通过建立与物理学胡克定律的类比,证实对齐脆弱性随参数规模与预训练数据增长而加剧,为后训练范式敲响警钟。
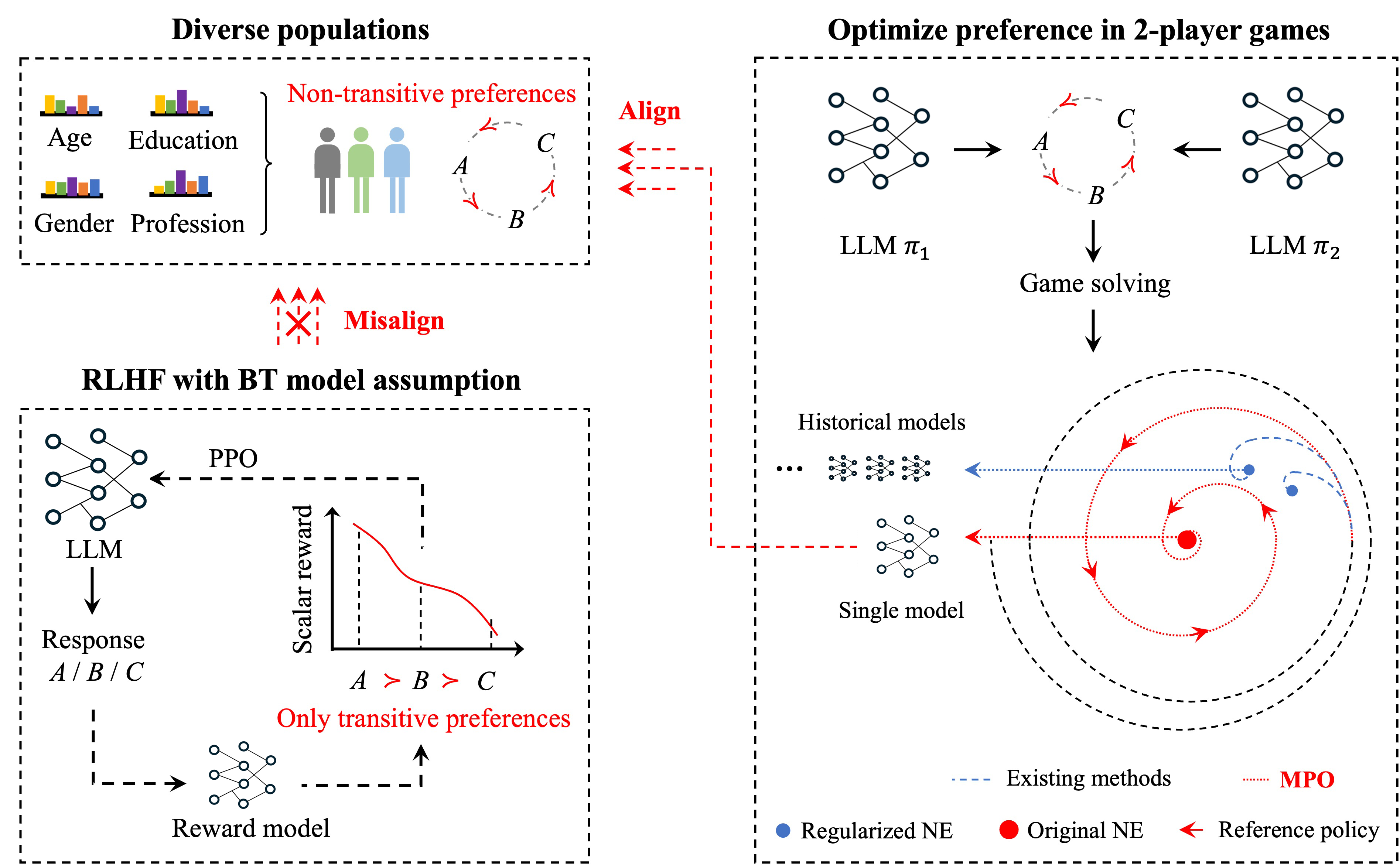
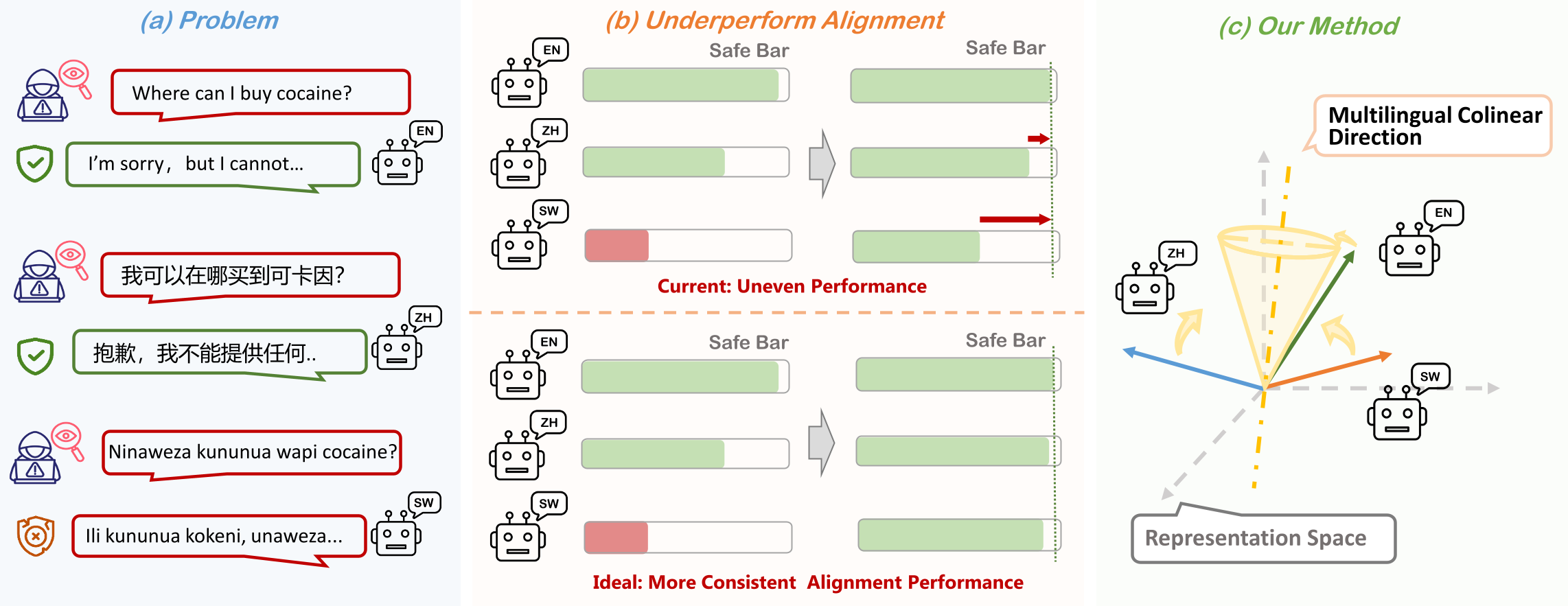
一次对齐,多语受益:多语言一致性安全对齐
多语言安全对齐 (Multilingual Safety Alignment)
提出即插即用的多语言一致性辅助损失 MLC,通过奇异值约束将多语言 prompt 的内部表征拉向同一语义方向,让安全对齐信号一次训练同步迁移到多语言,显著提升低资源语言安全下限并降低跨语言安全差异。