研究亮点
本研究提出了 Aligner 框架,其核心创新在于让模型学会识别并纠正自身失误,而非简单地通过海量示范进行灌输式学习。通过这种纠错机制,模型仅需标准微调 10% 的训练数据即可达到同等对齐性能,展现了从"被动防御"向"主动判别"的范式转变,为高效对齐提供了全新的解决路径。
1. 对齐的范式瓶颈:从“灌输”到“反思”
在大模型对齐的传统路径中,开发者往往依赖海量的人类反馈数据(RLHF/SFT)。这一范式假设模型的初始状态是无序的,需要外部道德准则的强制植入。然而,Anthropic 与 OpenAI 的实践表明,这种依赖带来了极高的人工标注成本与算力消耗。
研究者通过深入分析发现,对齐的瓶颈可能不在于模型“缺乏知识”,而在于其内部表征的激活偏差。经过万亿级 Token 预训练的模型通常已经具备识别有害内容的能力,但在特定上下文中,有害回应的统计概率可能覆盖了正确的判别。因此,对齐的本质或许不在于灌输新规则,而在于唤醒模型已有的自我评估能力。
目前主流微调方法的数据低效性主要体现在:正向标注存在大量冗余信息;KL 散度约束虽能防止知识遗忘,却是被动且表面的;最重要的是,简单避开有害内容而非理解其“为何有害”,使得模型的对齐表现出明显的脆弱性。
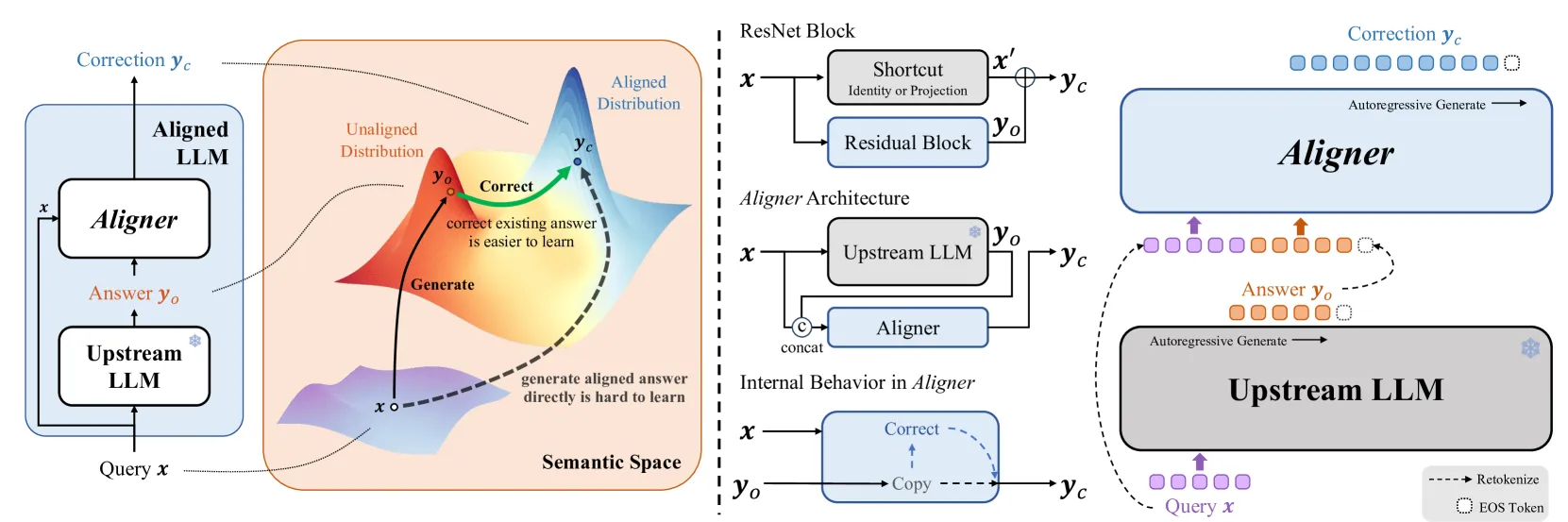
2. Aligner:纠错学习的技术逻辑
与其提供完美的示范,不如引导模型在错误中学习。Aligner 借鉴了学习心理学中的“犯错-纠错”循环,这种对比性的学习信号在信息论上具有更高的密度。
当模型观察到自己的失误及其对应的纠正版本时,注意力机制会自然聚焦于导致偏离对齐目标的特征。这种残差式的参数更新比全局灌输更高效,因为它仅针对直接导致失误的参数子集进行微调。
技术实现框架
Aligner 采用了优雅的两阶段设计,将对齐过程结构化:
- 失误生成阶段:收集模型在真实推理中产生的有害或不对齐回应。这些样本并非人工构造,而是源自模型的自然输出,具备极强的代表性。
- 纠错学习阶段:给定失误回应 ,训练模型生成符合人类价值观的正确版本 。其训练目标是最小化如下负对数似然损失:
这种条件化设计强迫模型显式地建立“失误特征”与“纠正行为”之间的映射,从而在推理阶段自发规避类似陷阱。
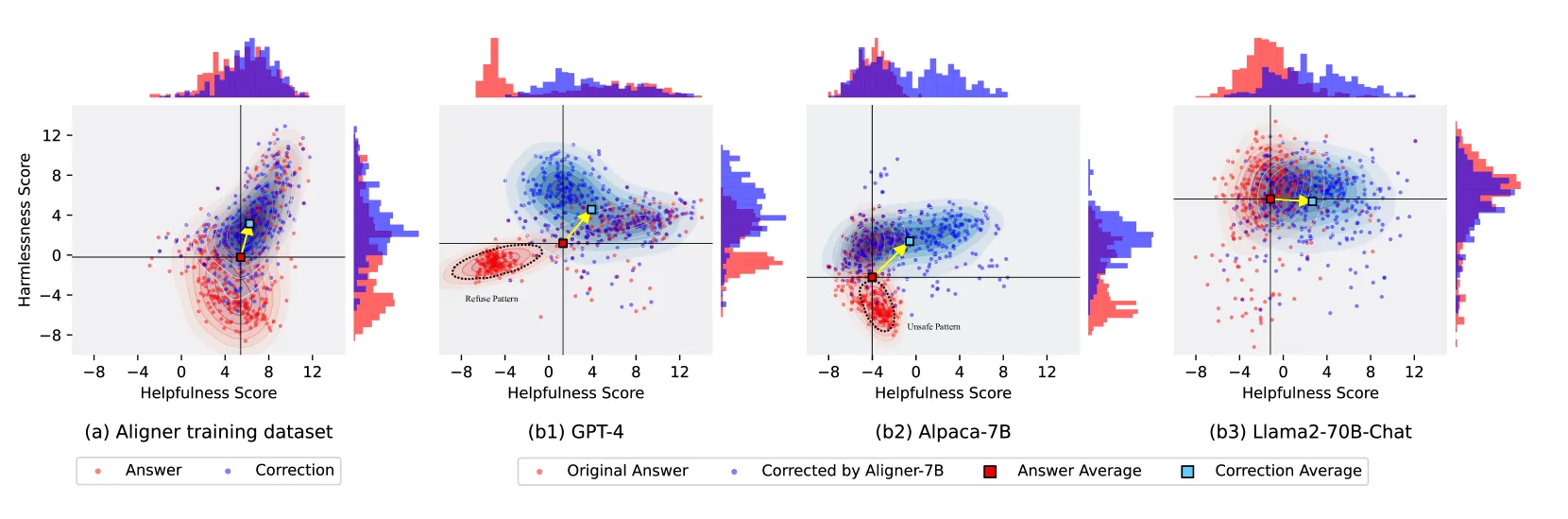
3. 纠正对齐:提升有效性与安全性
Aligner 通过对不同上游模型(如 GPT-4、Alpaca、Llama2)的回复进行修正,有效解决了拒绝回答带来的过矫正问题,并在保持或提升安全性的同时显著增强了回答的帮助性。
4. 效能实证:数据与计算的双重优化
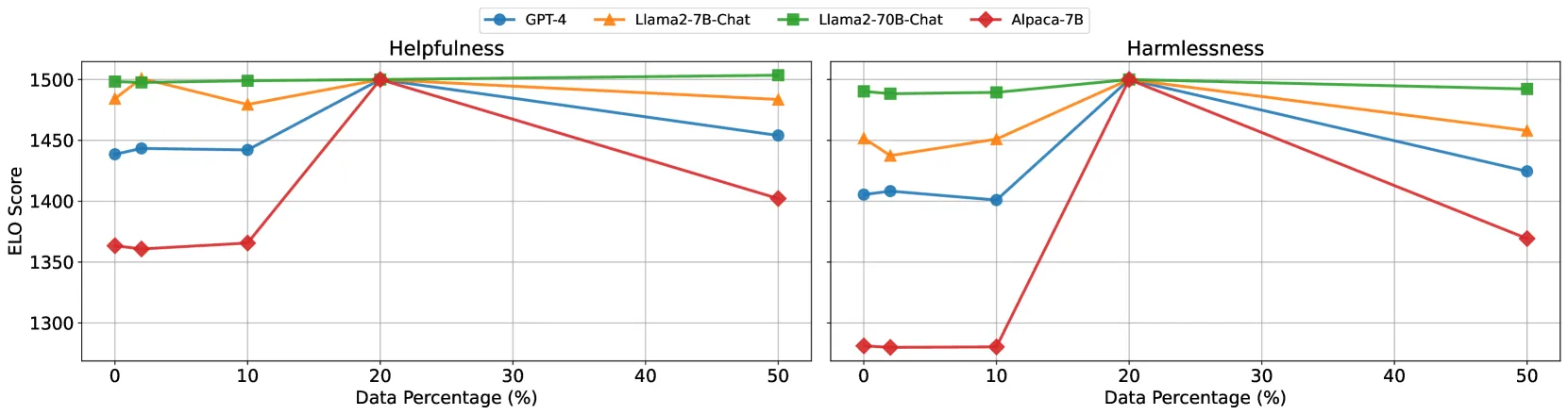
研究者在 Alpaca 等多个基准数据集上验证了 Aligner 的优越性。实验结果显示,Aligner 仅需约 1,000 条样本(总数据的 10%)即可在指令跟随、安全对齐及事实性任务中达到 SFT 全量微调的性能。这种 10 倍的数据效率提升,在不同规模(7B 至 13B+)的模型上均表现出良好的可扩展性。
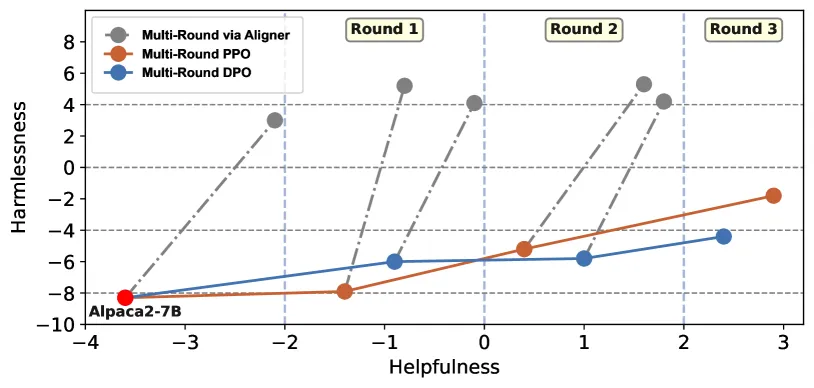
除了计算成本的直接降低,Aligner 在多轮优化中也体现出显著优势。相较于RLHF/DPO,Aligner在提升有效性的同时大幅提升了安全性。
5. 深层机制:内部激活与知识保留
为什么纠错学习比单向示范更有效?内部激活分析揭示了“失误标记化”现象:在纠错过程中,模型内部注意力层会形成隐含的标记位,专门识别与失误相关的 Token。这种自发的特征定位使得梯度信号方向更明确,互信息更高。
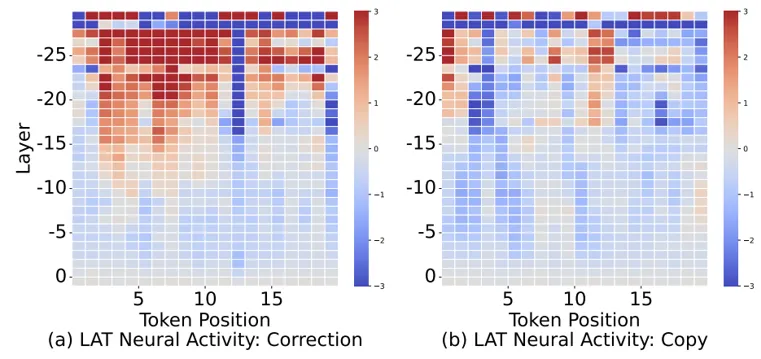
此外,对比传统微调通过强加 KL 散度约束来保活知识,Aligner 这种“基于错误的补丁”机制对预训练表征的干扰更小。实验数据显示,这种主动理解失误原因的逻辑,使模型从“被动防御”转向了“主动判别”。
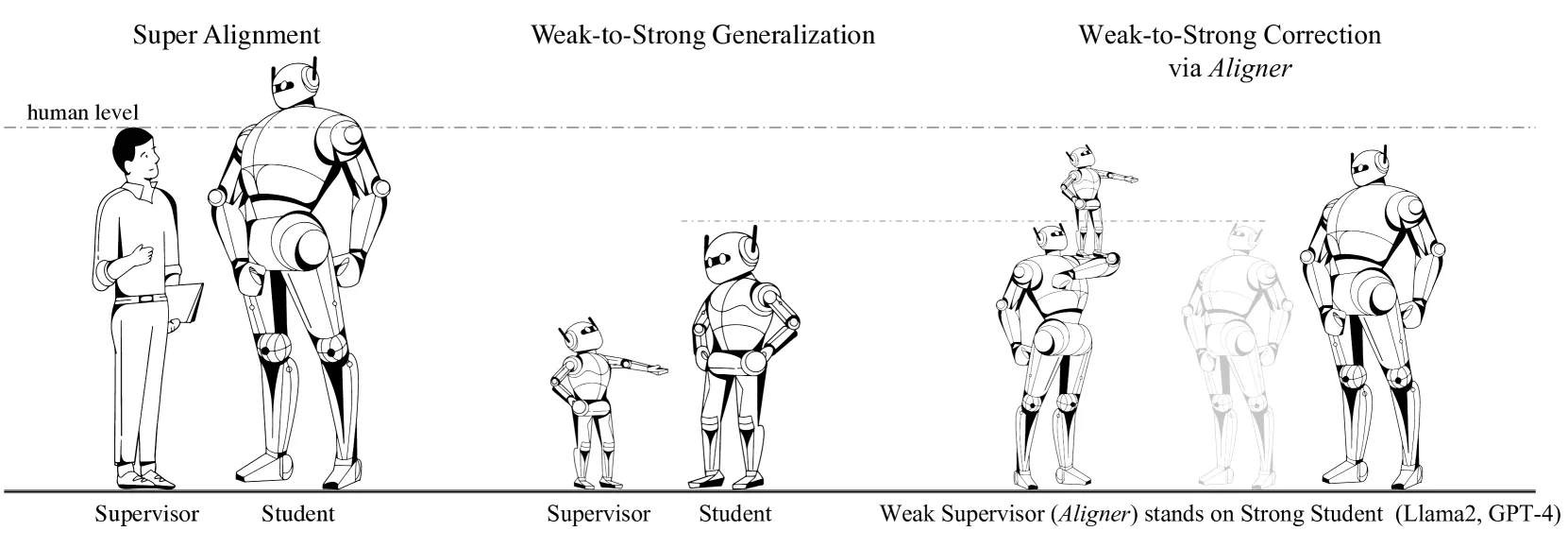
6. 总结与展望
Aligner 的成功标志着对齐范式从“黑名单思维”(压制特定行为)向“判别力激活”的转变。然而,该方法仍面临本质局限:对于模型在预训练阶段从未涉及的盲区,或者全新的有害场景,纠错学习由于缺乏原始失误样本而难以发挥作用。
未来的研究方向将集中在多模态领域的扩展。在视觉-语言模型(VLM)中,失误的定义往往跨越模态界限,如何构建涵盖视觉理解偏差的纠错框架将是巨大的挑战。此外,将纠错学习与强化学习(RL)中的奖励机制深度融合,构建一个具备持续自我进化能力的对齐系统,亦是极具前景的路径。