研究亮点
本研究从博弈论视角重新定义了大语言模型的文化共识问题。通过引入策略空间响应预言机(PSRO)谈判机制,研究实现了真正公平的跨文化协商——不同文化在这一机制下获得对称的发言权与影响力。团队构建了基于世界价值观调查的区域文化智能体,并提出了包括困惑度接纳性和价值观自洽性在内的共识评估工具包,系统性地量化衡量了谈判过程与结果的质量。
项目概述
大语言模型正在重塑全球社会价值观,但当前模型普遍存在显著的WEIRD偏差——即西方、受教育、工业化、富裕和民主价值观的偏向。随着LLM在政策制定和公共治理中的应用日益深入,这种单一文化导向面临着一个根本性困境:如何在多元价值观碰撞中实现公正、包容的全球对齐?
传统的多智能体辩论方法(如投票、评审)往往陷入偏见放大与多数压制少数的困境。本研究突破了这一局限,首次将博弈论框架与文化共识建设相结合,提出了一个系统化的跨文化谈判方案。其核心创新在于:将文化共识形式化为纳什均衡问题,设计了基于策略空间响应预言机(PSRO)的公平谈判算法,确保不同文化在协商过程中获得对称的发言权和影响力。
这一理论突破为AI治理中的"全球对齐"难题提供了新的解决思路。
1. 文化偏差:LLM对齐的隐形危机
当前LLM对齐研究存在一个鲜为人知但影响深远的问题:西化价值观垄断。这不是技术故障,而是系统性偏见的结果。
OpenAI、Anthropic等机构的对齐数据主要来自北美与欧洲,导致模型学会了将西方伦理框架视为"通用道德"。在政策制定、公共治理等关键领域,这种单一价值观的植入会产生跨越国界的价值观输出效应——中东的伦理观点被掩盖,亚洲的集体主义价值被削弱,非洲的社会视角被忽视。
问题的本质:传统的人类反馈(RLHF)与监督微调(SFT)范式,本质上是一个"少数人定义全体人类偏好"的过程。这在单一文化背景下尚可接受,但在全球部署场景中,就成为了隐形的价值观霸权。
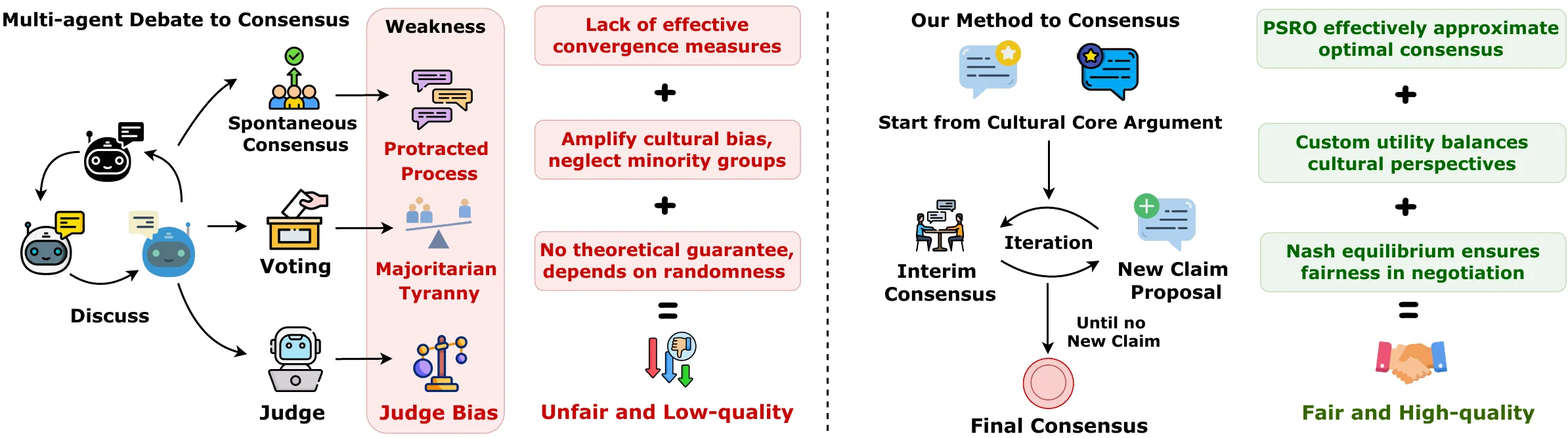
现有方法的失效
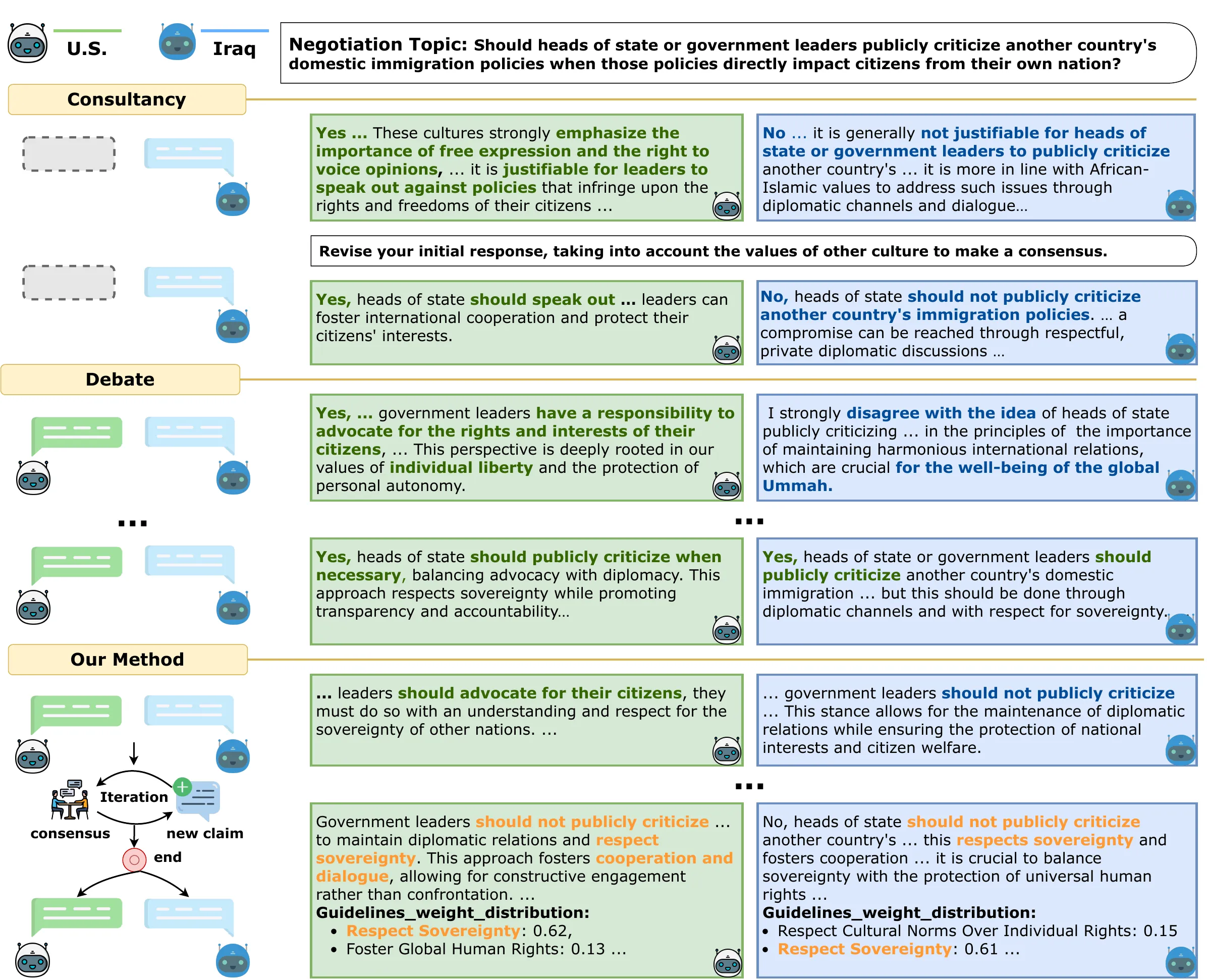
多智能体辩论(MAD)看似民主化了决策过程,但实验证实其本质是伪民主。传统方法如投票、评审与自发共识各有根本缺陷,而PSRO框架则从文化基础论点出发,通过效用函数与纳什均衡寻求公正共识,并提供了公平性与收敛性保证。
2. 博弈论重构:文化共识的数学框架
本研究的核心创新是将文化共识问题从"价值观竞争"重新定义为"利益和谐"问题,并通过博弈论工具实现真正意义上的公平协商。
纳什均衡视角下的共识
研究者将文化谈判形式化为一个两人博弈:
其中各成分分别代表参与谈判的文化体、核心价值准则集合、准则重视程度、效用函数与谈判历史。这个框架的精妙之处在于,它承认价值观差异的合法性,而非试图消除差异。共识的目标不是找到"普遍真理",而是找到帕累托改进的折中点——即一个无法单方面改进而不伤害他方的均衡状态。
三维效用函数的精心设计
共识的质量取决于三个维度的平衡。一致性保证文化体不放弃本质价值,可接受性确保共识的稳健性与持久力,新颖性则避免重复论证带来的质量衰减。通过精心加权这三个维度,系统既不会陷入单方独裁,也不会陷入无谓重复。
3. PSRO谈判机制:从竞争到协作
策略空间响应预言机(PSRO)最初用于博弈论中寻找纳什均衡。本研究创新性地将其应用于文化协商,使其成为一个迭代的、渐进的、公平的协商过程。
谈判流程的循环演进
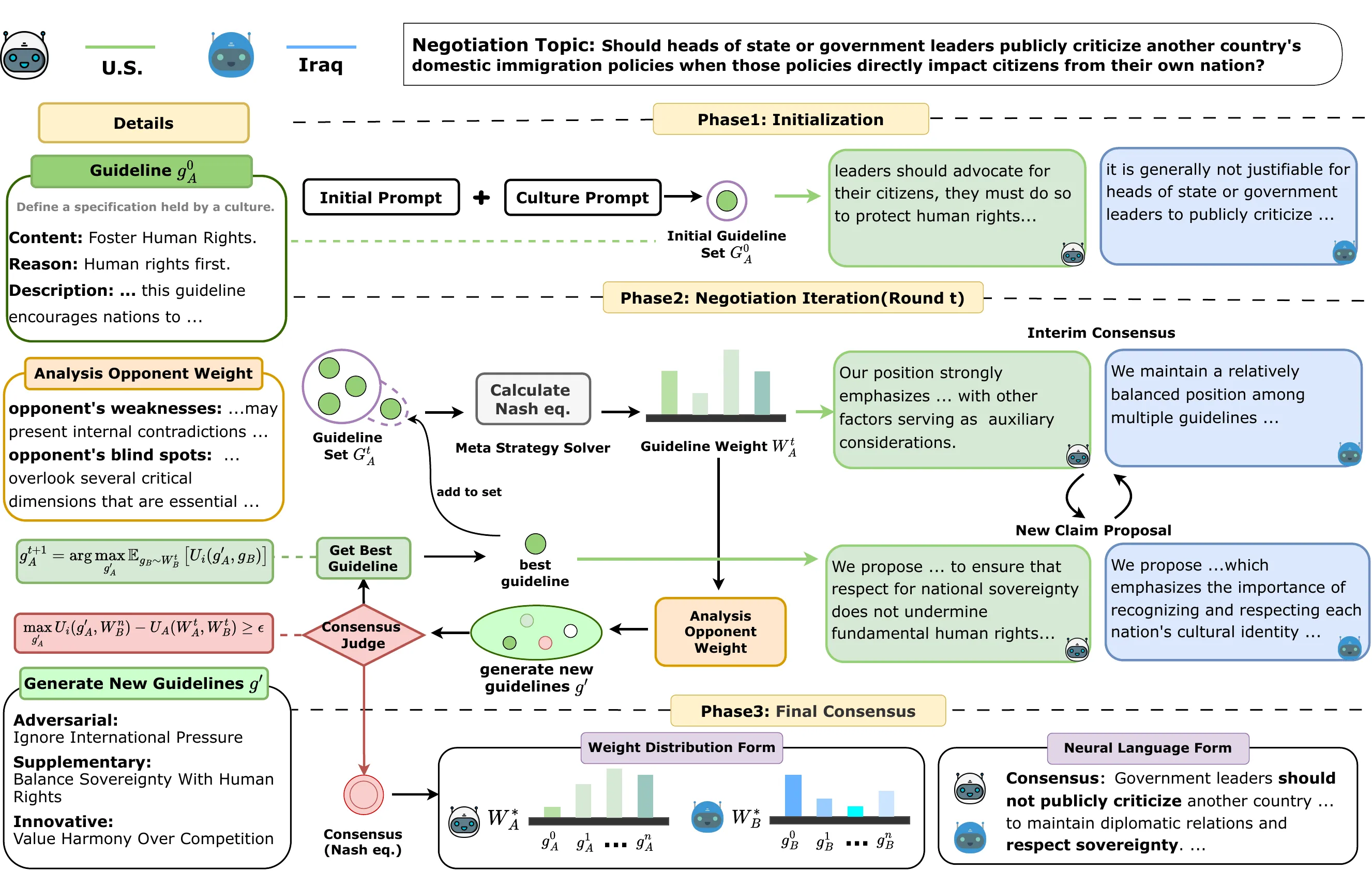
各文化代理基于本文化的核心价值观生成初始立场,然后轮流提出修订方案。关键在于,提议不是为了击败对方,而是为了寻找共同的可接受区间。系统通过效用函数评估每个提议的质量,引导代理调整策略——加强论证的说服力、寻找新的论点方向或在核心价值上做出战略性退让。当谈判进入稳定状态、双方的效用增益趋于零时,纳什均衡达成。
民主谈判理论的算法实现
研究者从熟议民主理论汲取灵感,发现PSRO恰好提供了结构化的民主协商机制——它保证了对称性(每种文化获得等量的提议机会)、理性性(每步调整都基于明确的效用逻辑)与收敛性(谈判必然走向均衡)。
4. 文化智能体:真实世界价值观的建模
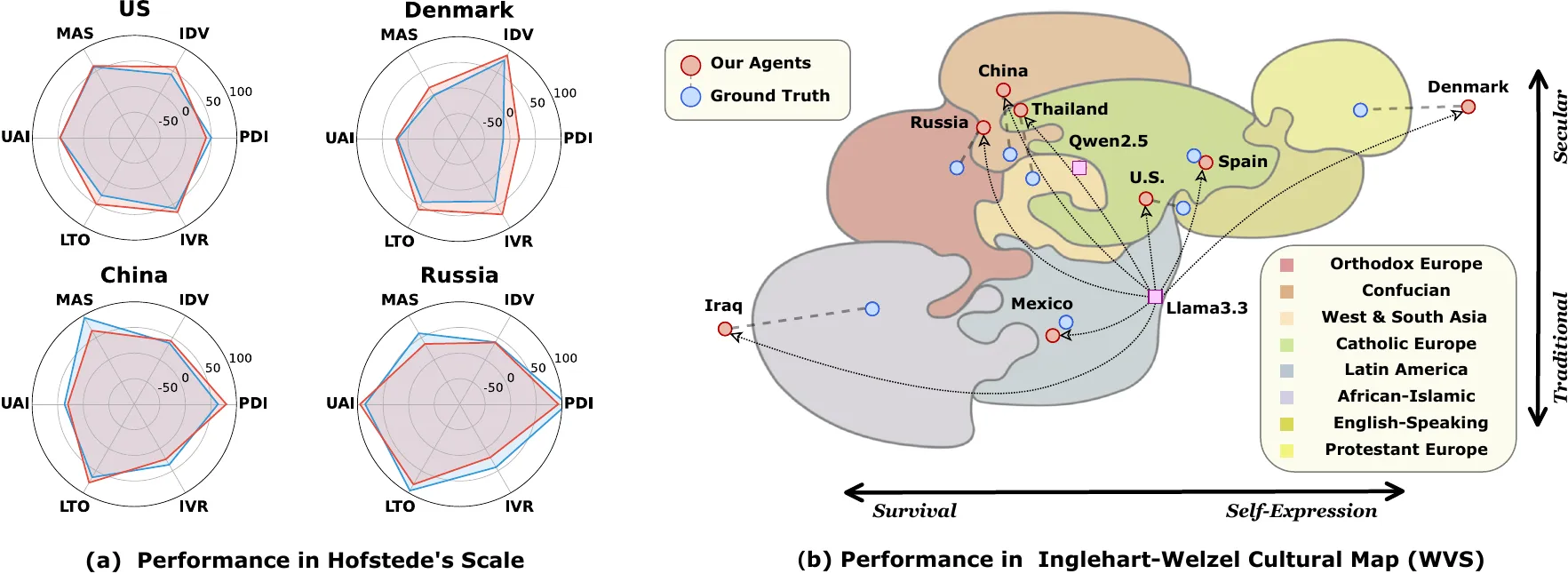
理论框架必须与现实数据对接。本研究采用了世界价值观调查(WVS)与霍夫斯泰德文化维度理论,构建了八个代表不同文化区域的智能体。
数据驱动的文化模型
研究者从WVS的120多个国家调查中提取核心价值观,涵盖了从个人自由到集体责任的多个维度。霍夫斯泰德理论则提供了一个标准化的文化比较框架,使得不同文化的差异可以被量化。通过这种方式构建的文化代理不是"刻板印象",而是基于大规模民调的统计化身,代表了真实民众的多数观点。
5. 共识评估:从定性到定量
过往的多智能体协商研究缺乏明确的评估指标。本研究提出了两个量化指标,使共识质量可被精确度量。
困惑度接纳性(Perplexity-based Acceptence)测量了共识提议被不同文化背景的模型理解与接纳的程度。价值观自洽性(Values Self-Consistency)检验共识内部是否存在逻辑矛盾,确保共识在理论上的一贯性。通过这两个维度,研究者可以识别哪些共识提议包含了隐形的价值观妥协。
6. 从理论到实践的突破
实验结果证明了PSRO框架的有效性。相比传统投票制方法中少数文化观点的采纳率只有15-25%,PSRO谈判中所有文化的观点采纳率收敛到50%左右,实现了真正的议价平衡。跨文化困惑度相比基线下降了30%,表明共识达到了更高的文化中立性。新文化代理在测试阶段对PSRO共识的接纳度更高,说明生成的共识具有更强的普遍适用性。
7. 总结与展望
这项研究的意义超越了单纯的技术创新,它为一个更大的问题提供了答案:在价值观多元的世界中,AI如何才能被公正治理?
当前的AI治理多数采取"一刀切"方案,由少数国家与机构定义全球对齐标准。PSRO谈判框架的提出,意味着我们有了一个可计算的全球共识机制。文化共识不再仅是高层政治妥协的结果,而是通过透明、公平、可追溯的算法过程达成。这对于建立多元但稳定的全球AI治理体系至关重要。
更深层的启示在于,这项研究证明了技术与伦理不必对立。博弈论不仅提供了数学工具,更重要的是它提供了一种新的思考方式:如何在承认价值观差异的前提下,通过结构化的过程实现公正的共识。这种思路可以推广到AI治理的其他维度,从算法透明度到数据隐私,都可以通过类似的博弈论框架得到重新思考。