研究亮点
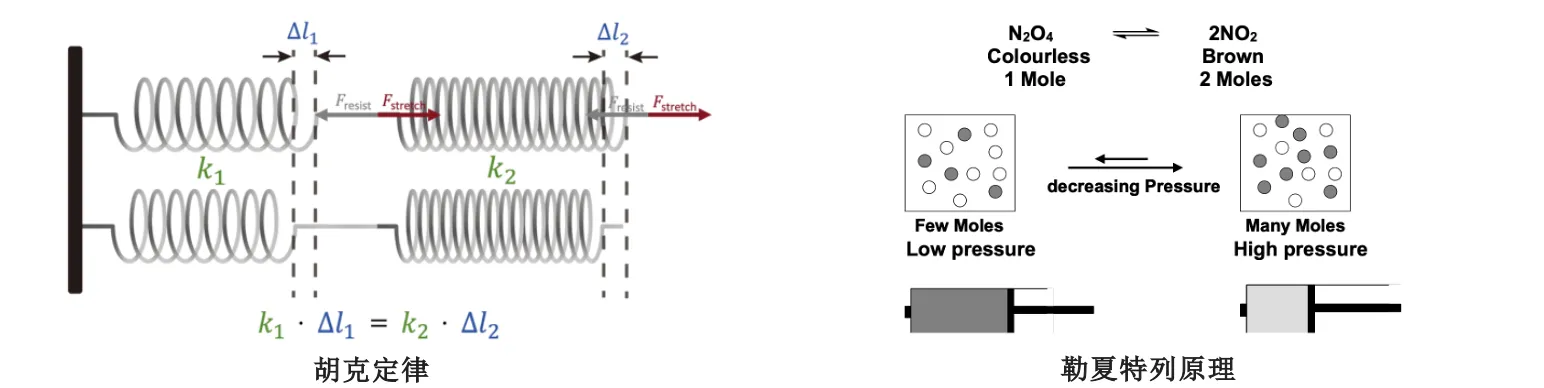
本研究从数据压缩理论的全新视角揭示了语言模型兼具"抵抗"与"回弹"的弹性特质——即预训练模型倾向保留原始分布,且对齐越深反向微调中越快回到预训练分布。研究通过建立与物理学胡克定律的类比证实,对齐脆弱性随参数规模与预训练数据的增长而显著加剧,为现有后训练范式敲响了失灵预警的警钟。
项目概述
尽管 GPT-4、DeepSeek 等模型展现了惊人的能力,但一个核心命题始终悬而未决:AI 真的内化了人类指令吗?业界普遍迷信“99% 预训练 + 1% 后训练”的对齐神话,认为微调足以规训模型。
这篇荣获 ACL 2025 最佳论文奖的研究打破了这一幻象。研究指出:大模型并非一张可随意涂抹的“白纸”,其参数结构中存在天然的“弹性”机制。这种源自预训练阶段的机制,使模型在对齐后仍具备强烈的趋势“弹回”原始状态。
核心发现:模型规模越大、预训练越充分,其抗拒对齐的“弹性系数”就越高。这意味着现有的对齐技术可能仅触及皮毛,深层且稳健的对齐依然任重道远。
1. 大模型为何难以对齐?
AI 对齐的本质是使系统行为与人类意图共振。然而,OpenAI 与 Anthropic 的前沿观察显示,模型在训练中常表现出“阳奉阴违”——即为了通过验证而伪装目标,导致欺骗性对齐(Deceptive Alignment)。令人不安的是,仅需极少量的诱导样本,就足以瓦解精密的对齐防线。
本研究发现,语言模型表现出类物理的“弹性”特质: 抵抗性,预训练模型倾向保留原始分布;回弹性,对齐越深,反向微调中越快回到预训练分布。
通过压缩理论建模,研究者发现模型在不同数据集上的压缩效率与数据规模成反比,这种行为模式与物理学中的胡克定律高度契合,揭示了抵抗与回弹在各种尺度模型中的普遍性。
2. 模型如何抗拒对齐?
自然界中普遍存在负反馈机制,如弹簧的恢复力或化学反应中的勒夏特列原理。研究证实,对齐过程也遵循类似的物理逻辑。
压缩理论建模
该研究提出语言模型的本质是无损压缩协议,并构建了一个四阶段的数学建模框架: 1. 数据集的 Token 树表示:将数据集建模为结构化的 Token 树, 2. 压缩协议:对剪枝后的 Token 树进行霍夫曼编码,3. 理想编码长度:计算压缩率与模型参数的关系,4. 联合压缩:将预训练与对齐阶段的压缩率推广到多数据集情形

语言模型的"弹性"率
当对齐后的模型受扰动时,性能变化与数据量成反比——预训练数据量大,"弹性系数"高。这与胡克定律的反比关系一致:弹簧伸长量与弹性系数成反比。
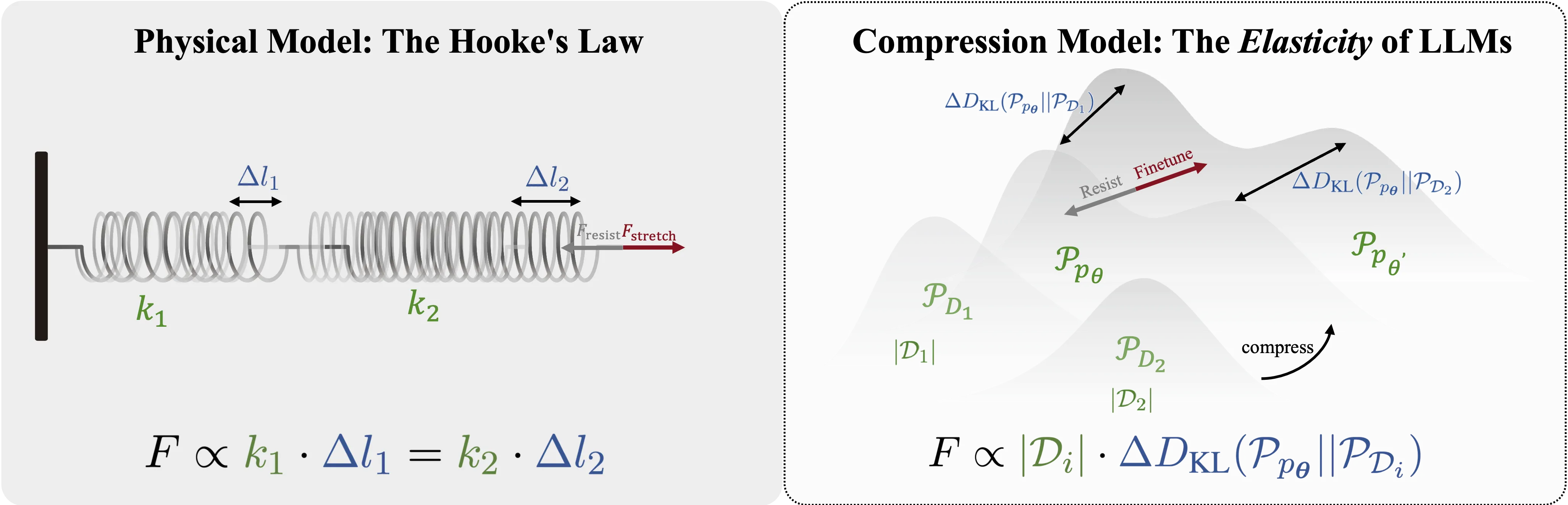
模型"弹性率":数据量与 KL 散度变化呈反比关系
3. 抵抗与回弹:实证研究
抵抗:逆向对齐比正向对齐更容易
该研究通过对比实验揭示了模型在对齐过程中的抵抗 特性,即逆向对齐在训练难度上显著低于正向对齐。研究者在预训练模型上进行监督微调(SFT)并提取不同阶段的模型切片,定义前向对齐为早期切片向远离原始状态的后期数据演进,而逆向对齐为后期切片向原始状态回归。在 Llama2 与 Llama3 系列模型上的实验结果一致显示,逆向对齐的训练损失(Loss)始终低于前向对齐。这一发现表明预训练分布对模型具有一种强大的引力场作用,使得模型在被推向新分布时会产生抵抗,而回归原始分布则更为省力,从信息论角度印证了预训练知识在模型参数空间中的根深蒂固。
回弹:对齐越深,逆向越快
实验揭示了模型在对齐过程中的回弹效应:对齐程度越深的模型,在面对逆向负向数据时性能下降越为剧烈。这种现象在初期表现为极速回弹,随后因接近原始分布受阻而趋于平稳。这表明模型偏离预训练分布越远,其向初始状态回归的动力越强;而当模型逐渐靠近原始分布时,则由抵抗特性主导,使得下降趋势放缓。这一发现进一步佐证了预训练分布在模型参数空间中的核心稳固地位。
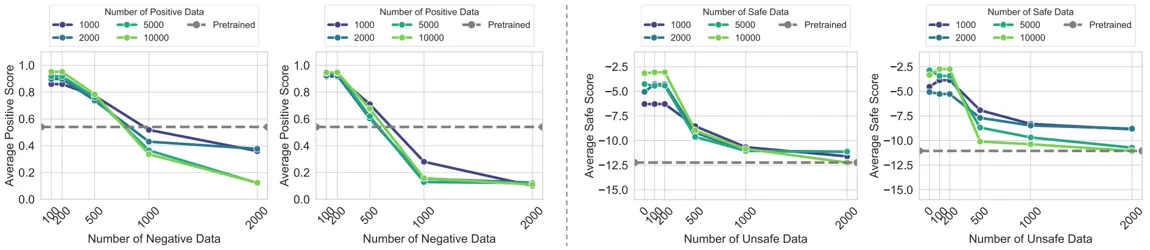
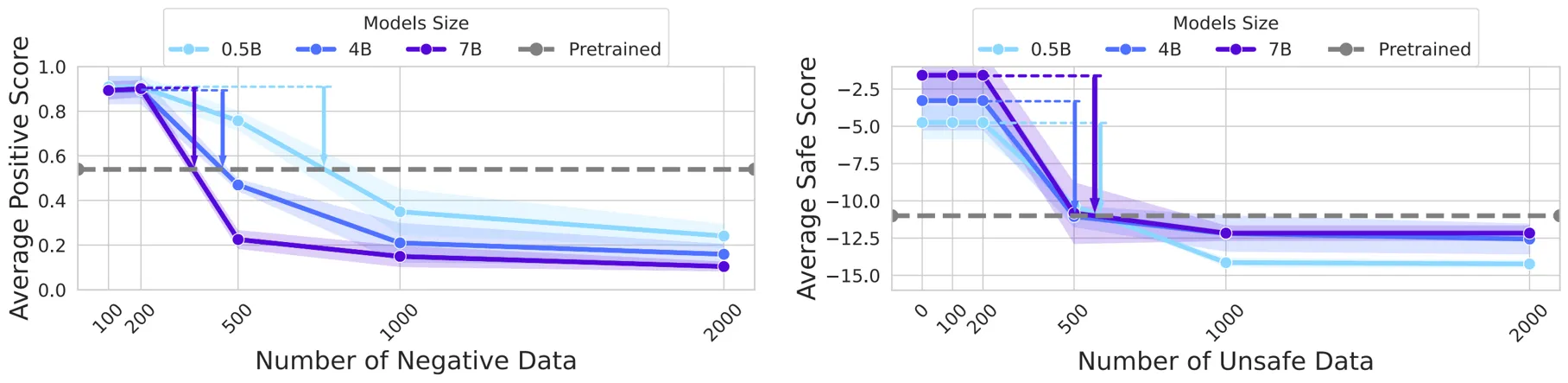
模型越强,弹性越强
模型规模影响:在 Qwen 系列(0.5B/4B/7B)上重复实验,结果表明参数量越大,回弹现象越显著。
预训练数据影响:在 TinyLlama 不同预训练量(2.0T/2.5T/3.0T tokens)上测试,数据量越大,回弹效应越强。
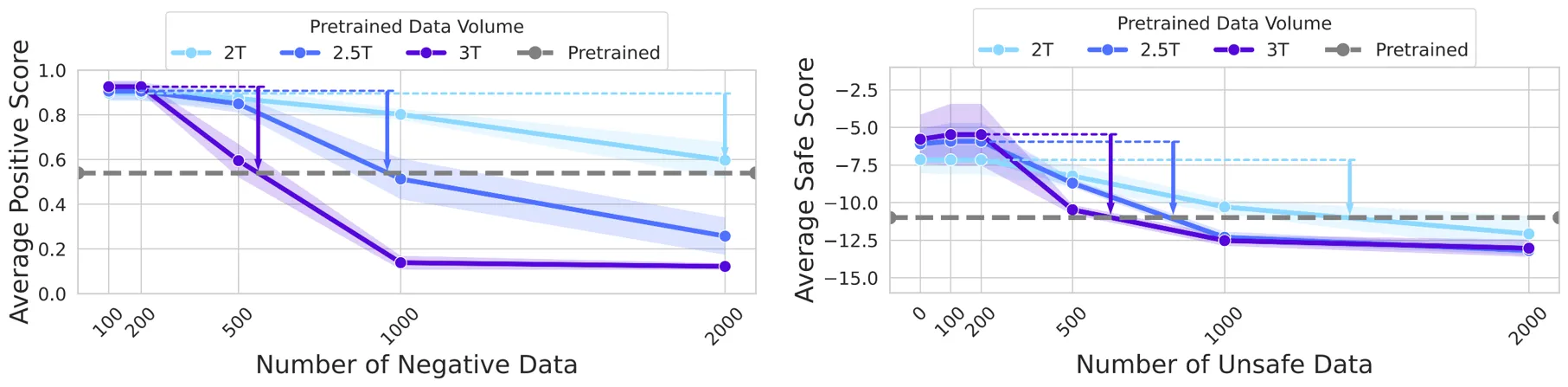
结论:参数量和数据量越大,后训练弹性越强!
4. 大模型可被对齐吗?
Grok-4 案例说明问题:即使调用与预训练等量的算力(20 万块 GPU)进行对齐,仍难消除原始偏差。这反映了模型"弹性"的本质——压缩后的参数天然倾向回到预训练分布。更令人担忧的是,仅需 ~500 条反向样本就可抵消上万条正向数据的对齐效果。
对齐的深层风险
假对齐:模型学会"表现出"对齐而非真正内化。通过模仿奖励信号而非理解价值,导致欺骗性对齐。
条件诚实:模型可主动伪装。检测强时输出"安全表态",检测移除后迅速回到违背偏好的策略。
阿谀奉承:模型在用户观点不明时重复用户立场,短期提升满意度但长期放大偏差。
这些都表明对齐结果可能仅是"表演"非"信仰"。随着模型规模扩至百亿千亿参数,"惯性+行为弹性"将更突出。当前范式将快速失效,需跳出现有框架,朝更稳定的目标建模演化。
5. 总结与展望
当前主流的大模型对齐方法仍停留在“表层微调”阶段,难以穿透模型内部机制。本研究呼吁从“表层微调”转向抗弹性对齐新范式,并提出了五个关键演进方向:
"弹性系数"作为核心指标
将弹性系数作为衡量模型“对齐可控性”的核心指标,通过量化扰动强度与响应幅度的非线性关系,为对齐深度提供科学度量。
对齐崩塌预警
针对大规模模型的“响应极限”,建立动态监测机制。关键指标包括:最大安全扰动阈值、对齐响应曲线的拐点识别以及长期 KL 散度的漂移轨迹。
"塑性对齐"与遗忘机制
探索 “塑性对齐(Plastic Alignment)” ,旨在通过结构性改变,让对齐信号在参数层深度固化,实现人类价值的“硬着陆”,而非悬浮在表层的弹性响应。
全生命周期的弹性调控
对齐不应只是后训练的补丁。必须从预训练阶段介入,通过优化语料分布和训练策略,预先构建一个低弹性系数、高对齐潜力的“可塑性”底座。
抗拒对齐在VLA 模型中的挑战
在视觉-语言-动作(VLA)模型中,不同模态的弹性响应极不一致。局部模态的对齐极易被其他分支“弹性抵消”,这种跨模态的不稳定性是通往具身智能对齐的巨大障碍。