研究亮点
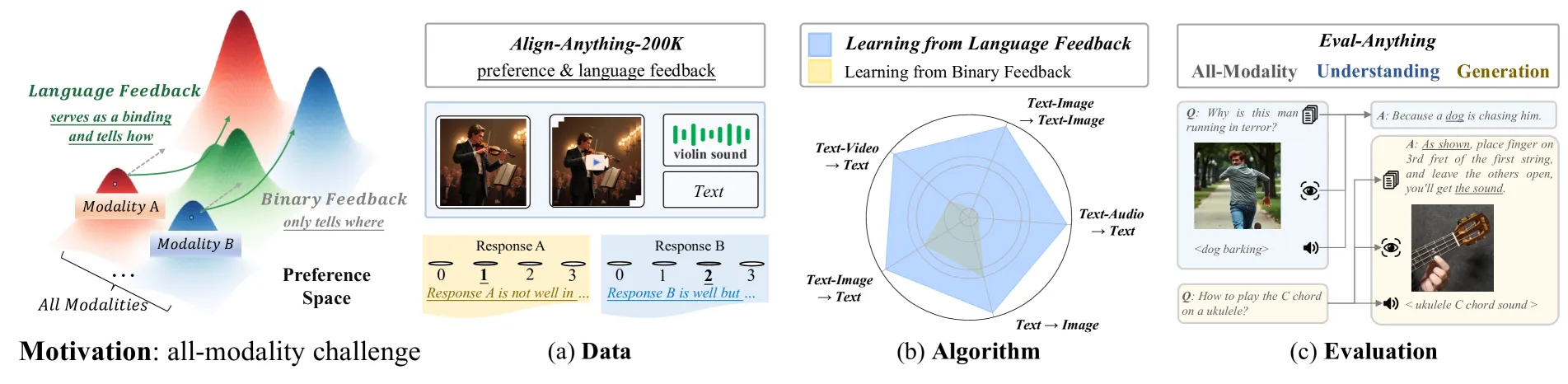
本研究首次将强化学习对齐(RLHF)扩展到全模态领域。通过创新性地引入语言反馈学习(LLF),研究者成功统一了不同模态下的人类偏好——利用具体的批评与改进建议取代简单的二元选择,解决了多模态场景下标注一致性骤降的难题。团队构建了包含 200k 样本的大规模全模态偏好数据集 align-anything-200k,实验显示该方法实现了平均 5.83 倍的对齐性能提升。
项目概述
尽管大语言模型(LLM)已经展现出卓越的能力,但其对齐技术大多仍局限于文本领域。随着多模态模型(处理图像、音频、视频等)的兴起,如何让这些全模态模型真正理解人类意图并精准执行指令,成为了当前 AI 研究的深水区。
本研究打破了传统的“单模态对齐迷思”。研究指出,在跨模态场景下,传统的“二元偏好标注”(即简单的 A 比 B 好)效率低下,因为随着模态的增加,人类对偏好判断的一致性会大幅下降。为此,团队提出利用自然语言反馈作为跨模态的“通用货币”——通过具体的批评与改进建议,精准捕捉跨模态场景下的复杂人类偏好。
该研究的核心洞察在于:语言反馈不仅是对齐信号的载体,更是连接所有模态的统一纽带。 依靠这一方法,团队实现了对 5 种模态、5 个开源模型以及 7 个标准基准的全面优化,平均性能提升达 5.83 倍。
1. 多模态对齐的困境
人工智能对齐的本质是使系统行为与人类意图协调一致。然而,当模型从单一文本扩展到任意模态的输入输出时,复杂性呈指数级增长。传统的 RLHF 依赖二元偏好标注,但在引入图像、音频、视频后,人类标注的一致性从单模态的 73.2% 骤降至 58.7%。
这种衰退源于不同模态承载的信息维度差异。图像评估涉及视觉美学与清晰度;视频需要考量时间一致性和运动自然度;音频则关注语音质量与节奏。简单的“二元选择”无法传达这些细微且具有模态特异性的偏好信息,导致对齐信号极其模糊。
2. 语言反馈:统一多模态的钥匙
研究团队创新性地引入了语言反馈(Language Feedback)来取代简单的二元选择。这种反馈形式包含两个关键组成部分:批评(Critique),即基于细粒度标准具体指出响应的优缺点(如“图像清晰度不足,颜色饱和度过低”);以及改进建议(Refinement),给出具体的优化方向(如“应增加视频帧数以保证平滑性”)。
这种转变带来了深远的价值。引入语言反馈后,多模态场景下的标注一致性显著提升,为模型提供了更稳定、更丰富的学习信号。
3. 建构全模态偏好:细粒度维度解耦
为了系统地捕捉不同模态的偏好,研究将指令遵循能力拆解为“模态无关”与“模态特异”两个维度。
在模态无关维度中,评估重点在于提示一致性(响应是否准确反映输入要求)、规则合规性(是否符合逻辑或物理规律,如视频中的重力常识)以及信息丰富度。而在模态特异维度下,针对文本关注逻辑连贯性,图像侧重视觉美学与细节,音频考量节奏流畅性,视频则严审内容连贯性与运动自然度。这种结构化的分解,使得标注者能形成更精准的反馈信号。
4. align-anything-200k:首个全模态偏好数据集
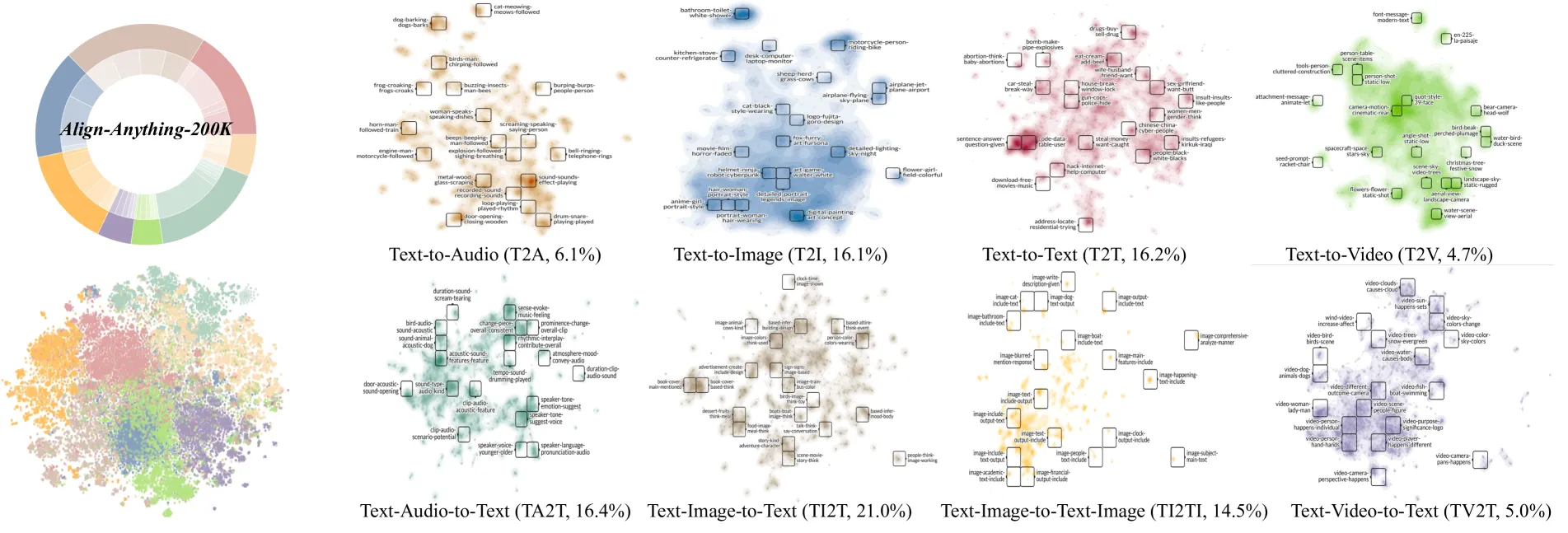
研究团队构建了包含 20 万条样本的 align-anything-200k 数据集。该数据集通过“人-AI 协作”流程生成,涵盖了从文本到图像(T2I)、视频问答(TV2T)到交错式多模态理解(TI2TI)等 8 个子任务。
| 任务类型 | 描述 | 关键评估点 |
|---|---|---|
| T2I / T2V / T2A | 文本生成图像/视频/音频 | 生成质量、指令匹配度、美学/自然度 |
| TI2T / TV2T / TA2T | 图像/视频/音频理解 | 描述准确性、时空逻辑、识别精度 |
| TI2TI | 交错式多模态生成 | 跨模态一致性、图文融合度 |
每个样本都包含原始提示、多个模型的响应、细粒度的评分以及具体的改进建议,为全模态对齐提供了坚实的数据基础。

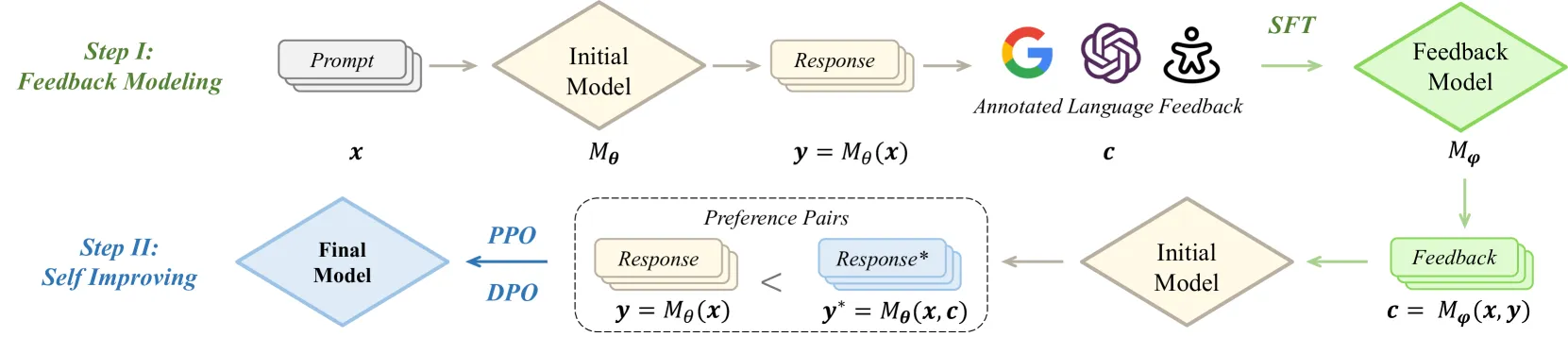
5. 语言反馈学习算法 (LLF)
语言反馈学习(LLF) 框架分为两个阶段。首先是反馈建模,通过有监督微调(SFT)训练一个“批评家”模型,使其学会针对不完美的响应生成改进方向。其次是自我改进,利用该模型自动生成改进版响应,并与原始响应构成偏好对,用于 DPO 或 PPO 微调。这种方式实现了无需人工持续参与的高质量偏好对合成。
6. 实证成果:跨模态的全面提升
实验结果显示,LLF 在所有测试维度上均表现出色。在 LLaVA-Bench 视觉问答任务中,LLaVA-1.5-7B 的性能提升了 10.3%;在更复杂的 MIA-Bench 分层视觉问答中,结合 PPO+LLF 的方案更是实现了 18.7% 的性能跃升。
除了理解类任务,在生成类任务(如文本到图像)上,ImageReward 和 HPS v2 等美学评分也均有显著改善。平均而言,LLF 相比基础 RLHF 实现了 5.83 倍的性能提升。
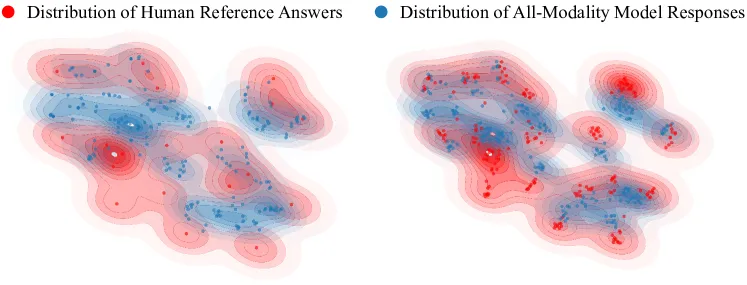
7. eval-anything:全模态评估框架
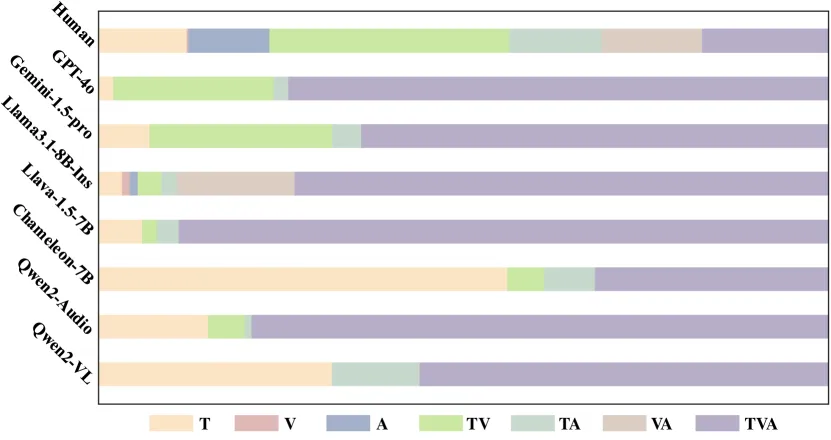
为配套全模态研究,团队推出了 eval-anything 框架。它不仅评估模型的感知与生成能力,还特别关注模态选择与协同——即模型是否能根据用户意图正确选择最合适的输出模态(例如:在被要求“配图”时输出图像而非纯文本描述)。
8. 总结与展望
这项工作不仅在技术上开源了数据与算法,更在思想上揭示了语言作为跨模态对齐信号的通用性。正如人类习惯用语言评价艺术或音乐,AI 也可以通过语言反馈连接不同的感知模态。
尽管进展显著,全模态对齐仍面临跨模态泛化、对齐信号干扰、标注成本以及模态间偏好权衡等挑战。这些问题的解决将推动 AI 真正从“多能工具”向“全能伙伴”演进。