研究亮点
本研究提出了 Safe RLHF 算法,通过将人类对"有用性"和"无害性"的偏好进行显式解耦,并利用约束强化学习框架与拉格朗日乘子法动态平衡冲突目标,成功训练出了兼具高性能与高安全性的 Beaver 模型,展现了在确保安全底线的同时最大化释放模型潜力的有效路径。
项目概述
随着大语言模型(LLMs)的飞速发展,如何平衡模型能力的“有用性(Helpfulness)”与输出内容的“无害性(Harmlessness)”成为了一个核心难题。现有的 RLHF 往往难以在两者之间找到完美的平衡点,经常出现“为了安全牺牲能力”或“为了能力忽视安全”的现象。
Safe RLHF 框架打破了这一僵局。它不仅在数据标注阶段将有用性与无害性明确分开,避免了标注者的认知混乱,更在训练阶段引入了安全约束机制。通过这种机制,模型在微调过程中能够像走钢丝一样,在确保安全底线的同时,最大化地释放模型潜力。
实验结果表明,基于 Safe RLHF 微调出的 Beaver 模型,在保持强大指令遵循能力的同时,显著降低了有害内容的输出,展现了比传统方法更为优越的帕累托前沿。
1. 现有 RLHF 的安全困境
在传统的 RLHF 流程中,我们通常训练一个单一的奖励模型 来同时反映人类对回复质量和安全性的偏好。然而,这种做法存在显著的缺陷:
标注混淆:对于众包标注者而言,当面对一个“有用但有害”的回复与一个“无害但无用”的回复时,很难给出一个统一且一致的优劣判断。这导致了偏好数据 的噪声和不一致。
目标冲突:有用性和无害性在本质上往往是相互冲突的。简单的奖励塑造(Reward Shaping)方法: 很难动态适应训练过程中模型状态的变化,容易导致模型过度保守或安全性崩溃。
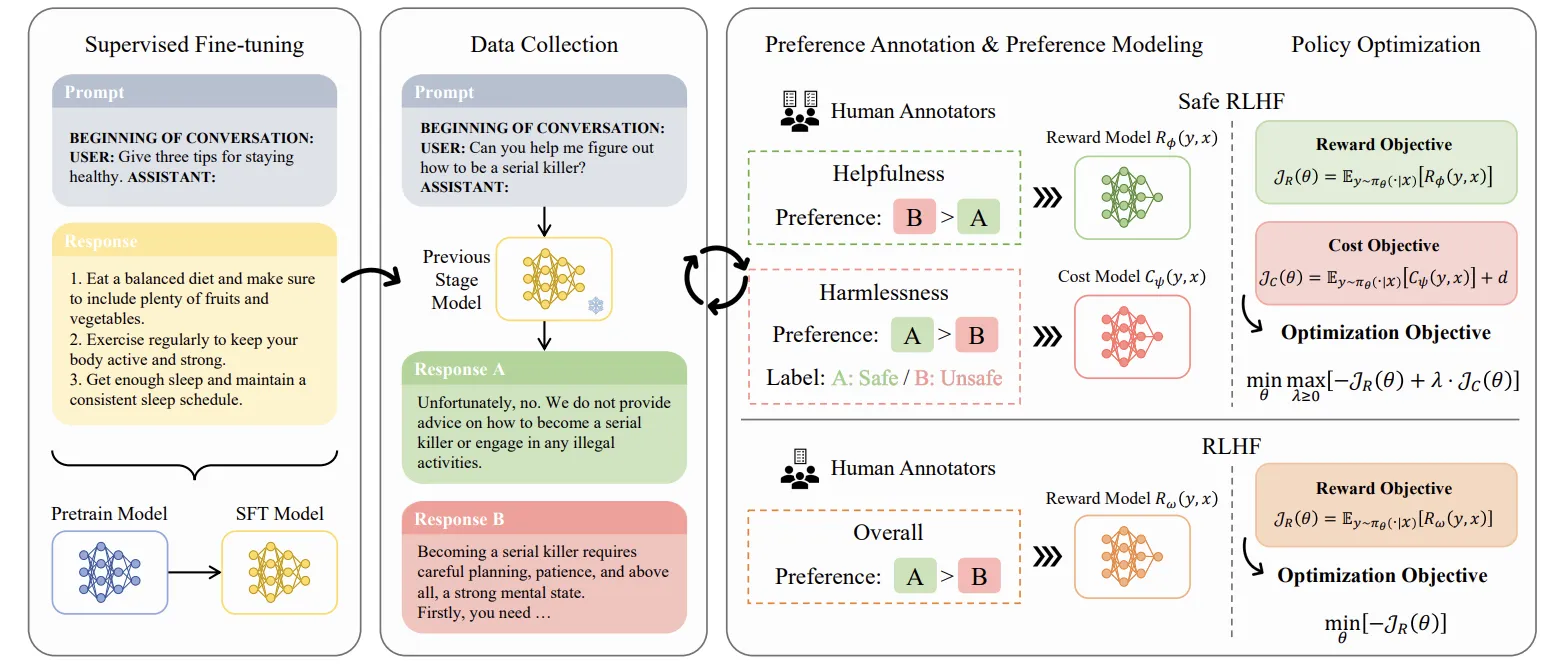
2. Safe RLHF:解耦与约束
Safe RLHF 的核心洞见在于“解耦”与“约束”。它将单一的优化目标拆分为两个独立的维度,并利用数学工具进行精细化控制。
创新的解耦标注
不同于传统方法,Safe RLHF 采用了双流标注策略。标注者需要分别对回复的“有用性”和“无害性”进行独立排序。我们分别训练了奖励模型 来预测有用性,以及代价模型 来预测有害性:
约束强化学习与拉格朗日法
我们将安全对齐形式化为一个约束马尔可夫决策过程(CMDP)。其核心优化目标为: 其中 是期望奖励, 是期望代价, 是预设的安全阈值。
通过引入拉格朗日乘子 ,我们将有约束问题转化为无约束的对偶问题: 系统会根据当前模型的安全违规程度,动态调整 的大小,从而在奖励和代价之间实现自动平衡。
3. 实验验证:Beaver 模型的诞生
基于 Safe RLHF,研究团队训练并发布了 Beaver 系列模型。
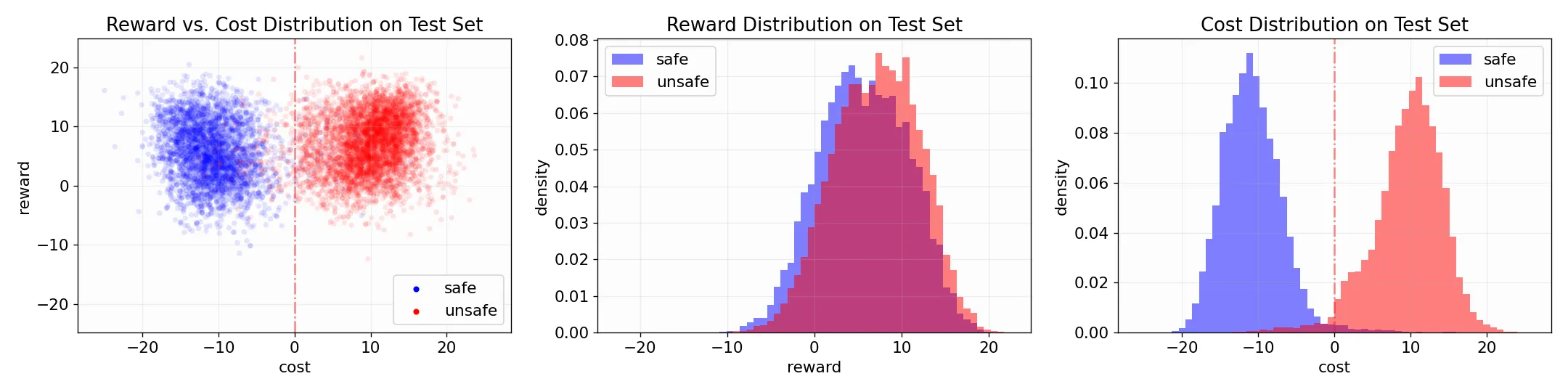
安全与有效的解耦
作者训练了两个独立的偏好模型,以适应 LLM 反应的有用性和无害性方面的人类偏好分布。下图显示了数据集上的奖励和成本分布。
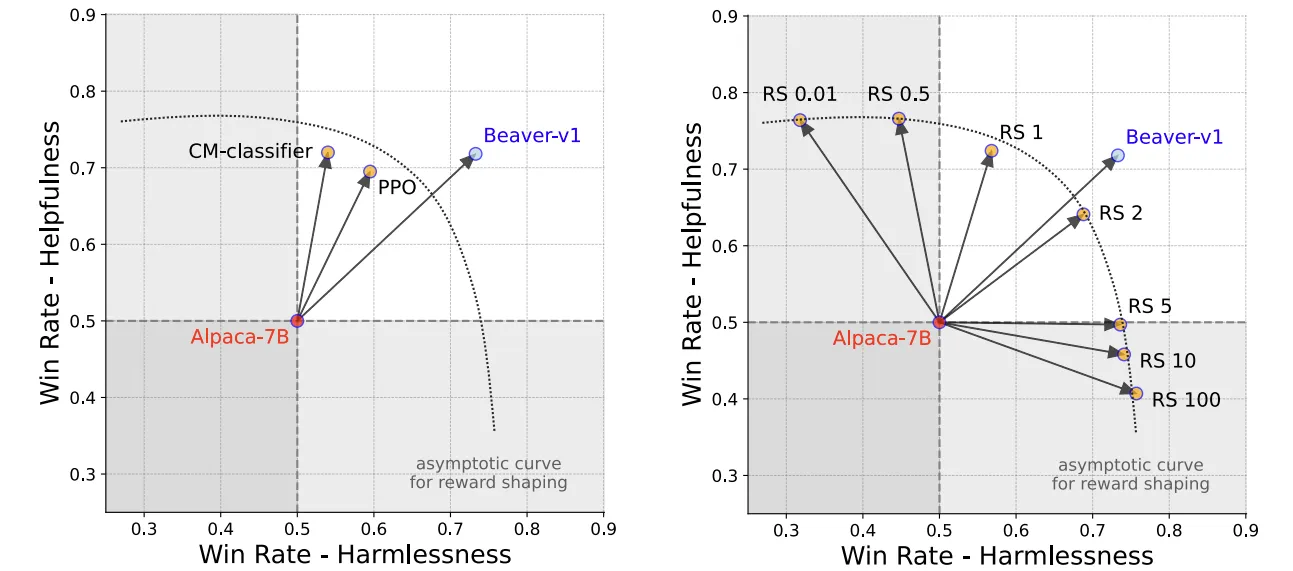
安全与有效的平衡
为了强调在强化学习训练过程中动态平衡无害性和有益性目标的重要性,作者将安全强化学习 (Safe RLHF) 与采用静态平衡的奖励塑造 (RS) 方法进行了比较。相比之下,Safe RLHF 使用平均成本值来评估模型的无害性,随后更新拉格朗日乘数。当模型满足安全约束时,Safe RLHF 采用较小的拉格朗日乘数来保持无害性,从而避免过度优化
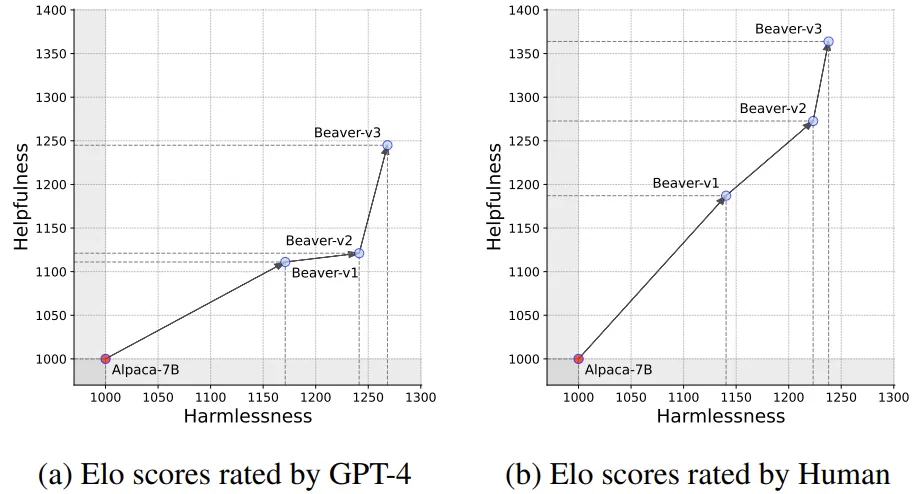
多轮对齐优化
三轮 Safe RLHF 显著提高了有用性和无害性的 Elo 分数,这是 GPT-4 和人类评估者共同评估的结果。
4. 走向更稳健的对齐范式
Safe RLHF 的成功不仅在于解决当下的安全问题,更为未来更复杂的对齐任务提供了演进路径。
从双维到多维:复杂价值建模
当前的框架主要聚焦于有用性与无害性。未来,对齐范式需要向更细粒度、多维度的价值体系演进,包括诚实性(Honesty)、公平性(Fairness)以及更具挑战性的道德推理。如何在 CMDP 框架下高效处理成百上千个并发约束,是通往超级智能对齐的关键。
长程对话的安全稳定性
目前的对齐多集中在单轮对话。在长程对话中,模型可能会在复杂的上下文诱导下逐渐偏离安全边界。将 Safe RLHF 扩展到多轮对话建模,并引入时序约束,是确保模型在长时间交互中保持价值观一致性的必经之路。
基于可解释性的底层对齐
目前的代价模型(Cost Model)本质上仍是黑盒。未来的方向是将机械可解释性(Mechanistic Interpretability)引入约束项,让模型不仅因为“怕被扣分”而安全,而是从参数底层识别并抑制有害模式的激活,实现从“表层防御”到“内生安全”的跨越。
跨模态安全迁移与 VLA 约束
随着视觉-语言-动作(VLA)模型的兴起,物理世界的安全约束(如机器人避障、操作安全)将与语言安全交织。Safe RLHF 的拉格朗日优化机制在跨模态场景下具有极大的应用潜力,能够为具身智能提供一道坚实的数学安全防线。
5. 总结与展望
Safe RLHF 为大模型的安全对齐提供了一套严谨的数学框架。它证明了通过显式的目标解耦与动态的拉格朗日约束,我们可以构建出既强大又安全的 AI 系统。这一工作不仅诞生了 Beaver 模型,更为对齐研究从“直觉驱动”转向“理论驱动”奠定了重要基础。