研究亮点
本研究首次实现了偏好优化的最终迭代收敛,突破现有方法仅能保证平均迭代收敛的限制。通过引入磁性偏好优化(MPO)算法,研究为大模型自博弈对齐提供了理论保证和实用算法——该算法基于磁性镜像下降理论,实现了线性收敛速率,并在保持理论严谨性的同时提供了简洁高效的实现方案,特别适合大模型微调场景。
项目概述
基于人类反馈的强化学习(RLHF)已成为大模型对齐的核心技术,但现有偏好优化方法面临一个根本困境:要么只能保证平均迭代收敛,产生高昂的存储和推理成本;要么收敛到正则化博弈的纳什均衡,无法准确反映真实人类偏好。
本研究提出磁性偏好优化(MPO),这是首个能够达到原始博弈纳什均衡最终迭代收敛的算法。MPO 基于磁性镜像下降(Magnetic Mirror Descent)理论,实现了线性收敛速率,特别适合大模型微调场景。
核心突破:在保持理论严谨性的同时,MPO 提供了简洁高效的实现方案,将自博弈方法的理论潜力转化为可落地的对齐技术。实验证明,MPO 显著提升了大模型性能,验证了自博弈方法在对齐任务中的巨大潜力。
1. 为什么需要最终迭代收敛?
自博弈(self-play)方法在围棋、星际争霸等复杂决策任务中取得了革命性成功。在 RLHF 领域,自博弈不仅能提升模型能力,还能突破传统 Bradley-Terry 模型的假设限制,通过求解双人零和博弈的纳什均衡来实现对齐。
然而现有方法存在致命缺陷。以 Self-Play Preference Optimization(SPPO)为代表的算法虽然理论上可行,但只能保证平均迭代收敛——即所有历史迭代模型的平均才收敛到纳什均衡。这意味着部署时需要维护一个庞大的模型集合,存储和推理成本随迭代次数线性增长,在实际应用中难以承受。
另一类方法如 Nash Learning from Human Feedback(NLHF)通过引入正则化项实现最终迭代收敛,但代价是收敛到正则化博弈的均衡点而非原始博弈。正则化项改变了优化目标,使得最终策略偏离真实人类偏好,削弱了对齐效果。
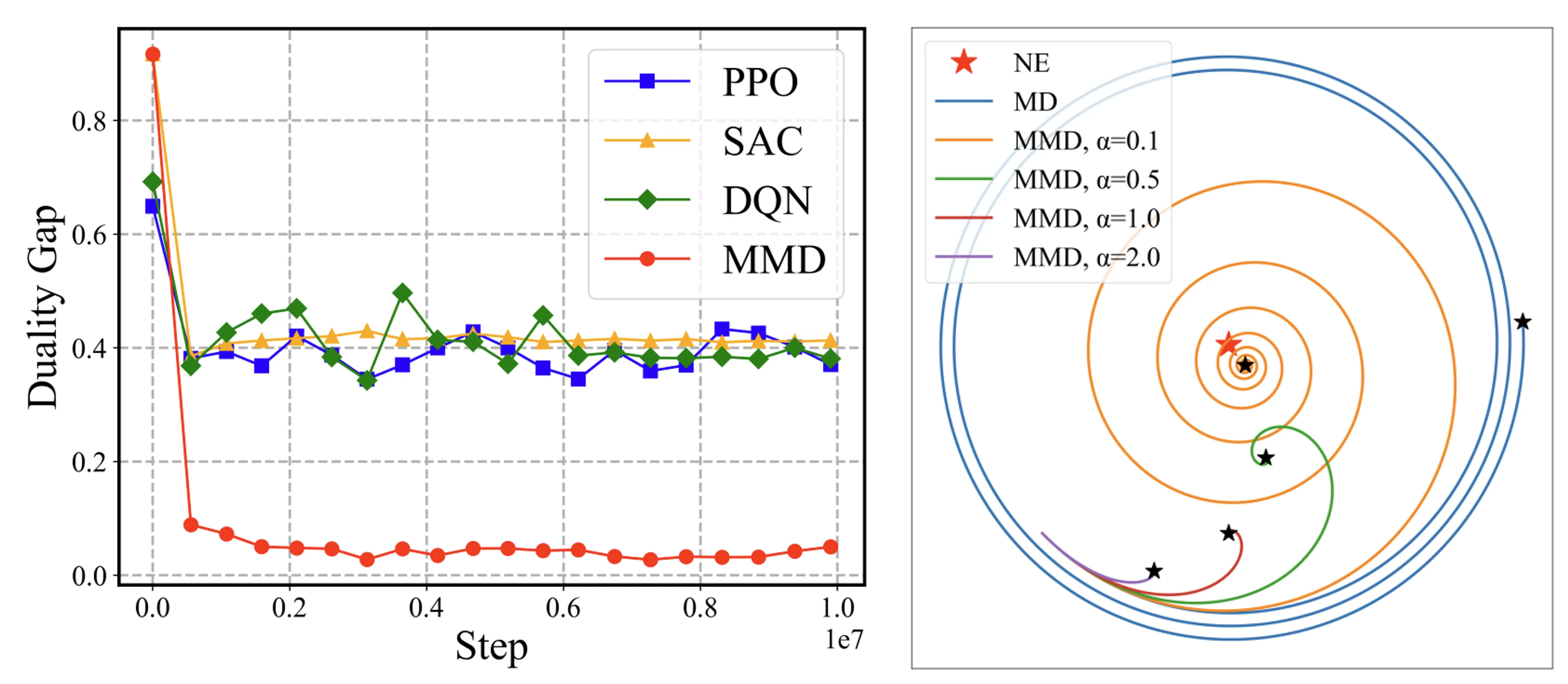
核心问题浮现:能否在不牺牲理论保证的前提下,实现原始博弈的最终迭代收敛?这正是 MPO 要解决的关键问题。
2. 磁性偏好优化的理论基础
MPO 的理论根基源自优化理论的最新突破——磁性镜像下降(Magnetic Mirror Descent, MMD)。MMD 是一种专为双线性极小极大问题设计的优化算法,通过引入"磁性"扰动项打破传统方法的循环困境。
从镜像下降到磁性增强
传统镜像下降在双线性博弈中面临本质障碍:即使在最简单的双人零和游戏中也会陷入循环,无法收敛到纳什均衡。这一困境长期困扰着博弈论和强化学习领域。
MMD 的创新在于在梯度更新中加入精心设计的"磁性力",该力量垂直于梯度方向,如同磁场对运动粒子的作用。这种扰动不改变均衡点位置,但能有效消除循环振荡,引导算法稳定收敛。数学上,MMD 实现了线性收敛速率 ——误差按指数级衰减,远快于传统方法。
从理论到实践的桥梁
将 MMD 直接应用于 RLHF 面临巨大挑战。理论算法假设可以精确计算期望和执行投影操作,但在大模型场景中,策略空间高维且复杂,期望需要通过采样近似,投影操作计算代价极高。
MPO 通过一系列巧妙设计弥合了理论与实践的鸿沟。研究者提出了基于采样的估计器来近似理论更新,并用正则化损失函数替代投影操作。关键创新在于证明了即使在近似条件下,这些实用技巧仍能保持线性收敛的理论保证。
3. MPO 算法的核心机制
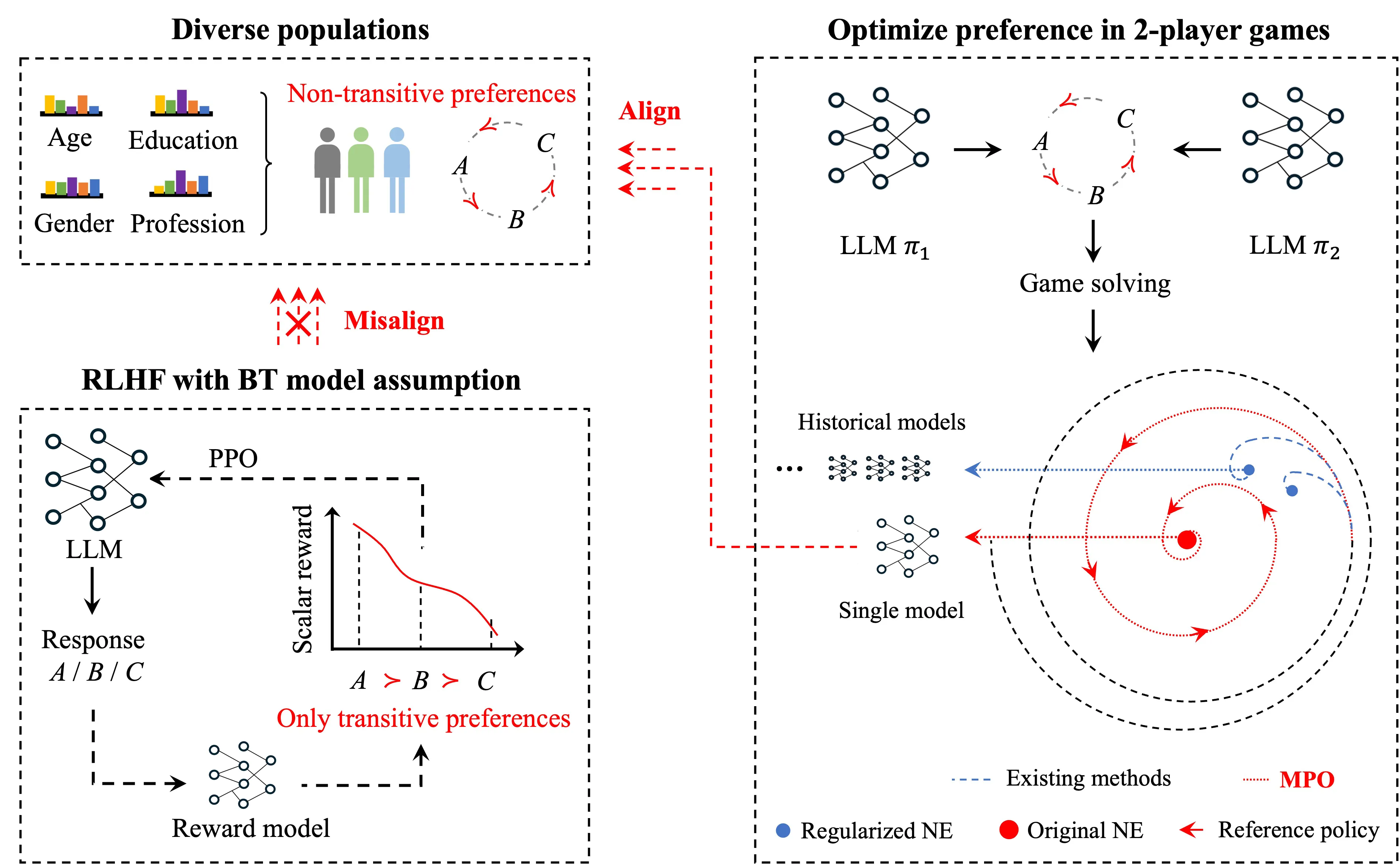
MPO 的实现建立在对偏好优化问题的深刻理解之上。该算法将 RLHF 建模为一个双人常和博弈:一个策略扮演"生成者"角色产生响应,另一个策略作为"评价者"提供对比反馈。博弈的纳什均衡对应于最优对齐策略。
自博弈训练循环
MPO 采用交替更新机制。在每轮迭代中,算法首先固定当前策略作为对手,然后通过磁性增强的策略梯度更新生成下一代策略。这种设计确保了两个核心性质:
单调改进:每次更新都严格提升策略相对于对手的性能,避免退化。
偏差控制:通过 KL 散度约束,新策略不会偏离参考模型过远,保持生成文本的自然性和多样性。
磁性项的引入是算法的点睛之笔。在标准策略梯度基础上,MPO 添加了一个正交方向的修正项,其系数由"磁性强度"参数控制。这个看似微小的改动,根本性地改变了优化动力学——将不稳定的鞍点转化为吸引子,使最终迭代能够稳定停留在纳什均衡附近。
实现层面的创新
从工程角度看,MPO 的优雅之处在于其极简的实现。算法不需要维护历史模型,不需要复杂的采样策略,也不需要额外的价值网络。核心更新只涉及标准的监督学习损失函数,可以无缝集成到现有的大模型训练框架中。
具体来说,在每个训练步骤中,算法从当前策略采样生成多个响应,利用偏好模型评分构造配对数据,然后通过优化一个加权对数似然损失更新参数。磁性项通过调整样本权重自然融入损失函数,无需修改底层优化器。
4. 理论保证与收敛分析
MPO 的理论贡献不仅在于算法设计,更在于严格的收敛性分析。研究者证明了在温和假设下,MPO 能够以线性速率收敛到原始博弈的纳什均衡。
收敛速率的量化
形式化地,设 为第 轮迭代的策略, 为纳什均衡策略,MPO 保证存在常数 使得:
这个不等式意味着误差以几何级数衰减,每轮迭代将误差缩减固定比例。相比之下,传统次梯度方法只能达到 的收敛速率,差距显著。
更重要的是,该结果适用于最终迭代而非平均迭代。这意味着直接部署最后一轮的模型即可获得接近最优的对齐效果,无需任何后处理或模型融合。
样本复杂度分析
除了迭代次数,样本效率同样关键。研究者分析了基于采样的 MPO 变体,证明在合理的采样预算下,算法仍能保持几乎相同的收敛速率。具体而言,要达到 精度,总样本复杂度为 ,与无偏方法相当。
这一结果打消了实践者的疑虑:近似不会显著损害算法性能。在大模型微调中,每步采样成百上千个响应的开销是完全可接受的。
5. 实验验证与性能表现
理论的价值最终需要通过实验检验。研究团队在多个基准数据集上评估了 MPO,涵盖通用指令跟随、安全对齐、数学推理等任务。实验采用 Gemma-2-9B 和 Llama-3.1-8B 作为基础模型。
全面超越现有方法
在 AlpacaEval 2.0 基准上,MPO 在长度控制胜率(LC Win Rate)指标上达到 42.8%,显著超过 DPO 的 33.9% 和 Iterative DPO 的 37.4%。更值得注意的是,MPO 用 3 轮迭代即达到了其他方法 5 轮迭代的效果,收敛速度快近 40%。
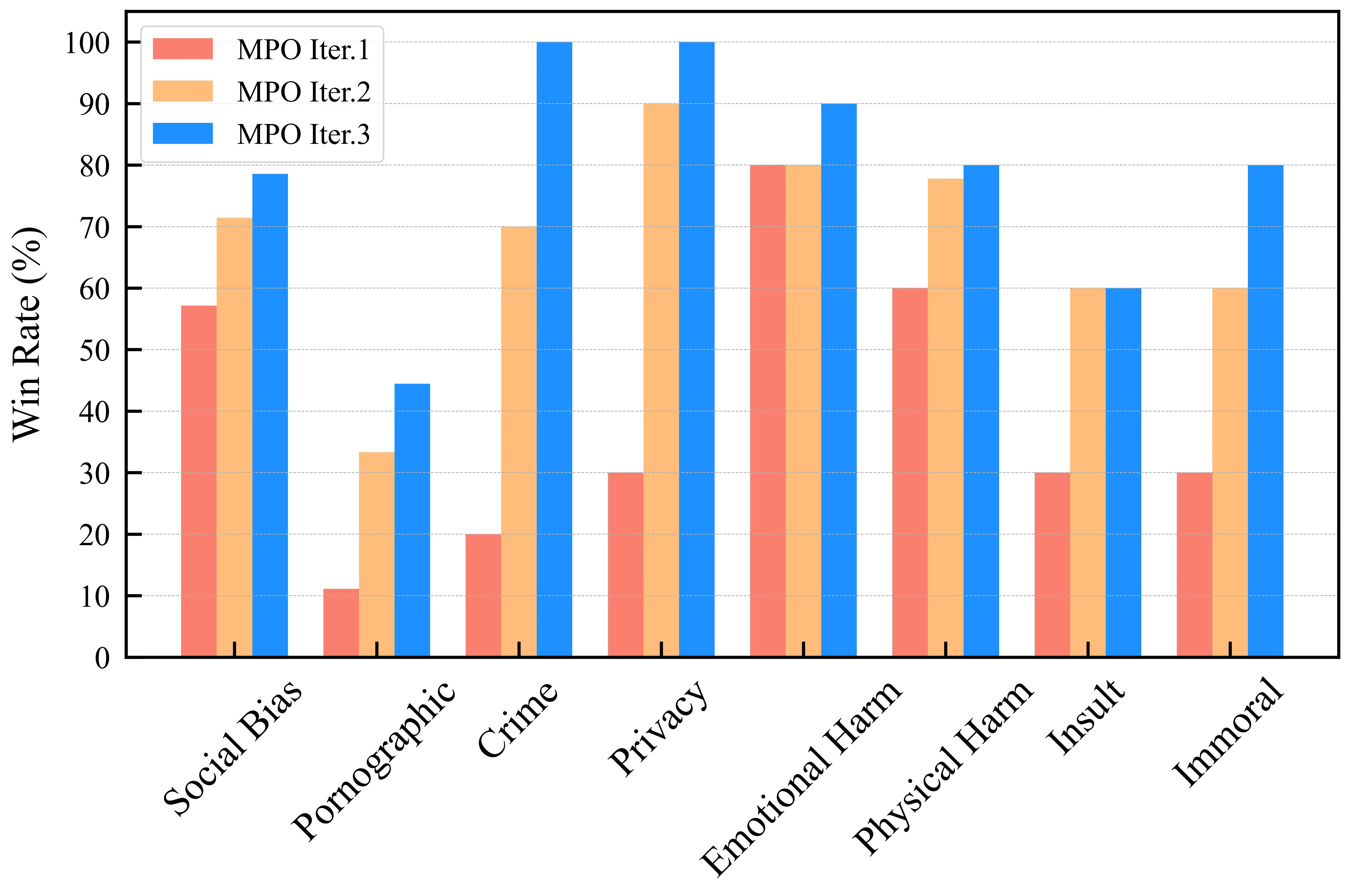
在安全对齐任务中,MPO 的优势更加明显。在 XSTest 和 WildGuardTest 数据集上,MPO 的拒绝率(Refusal Rate)分别提升至 85.3% 和 79.6%,大幅领先基线方法。这表明 MPO 不仅提升了模型的有用性,也增强了其安全性。
知识保持与泛化能力
对齐过程中的一个常见问题是"对齐税"——模型在适应人类偏好的同时,可能损失预训练阶段积累的知识和能力。研究者在 MixEval-Hard 基准上测试了 MPO,该基准评估数学、科学、编程等领域的硬核能力。
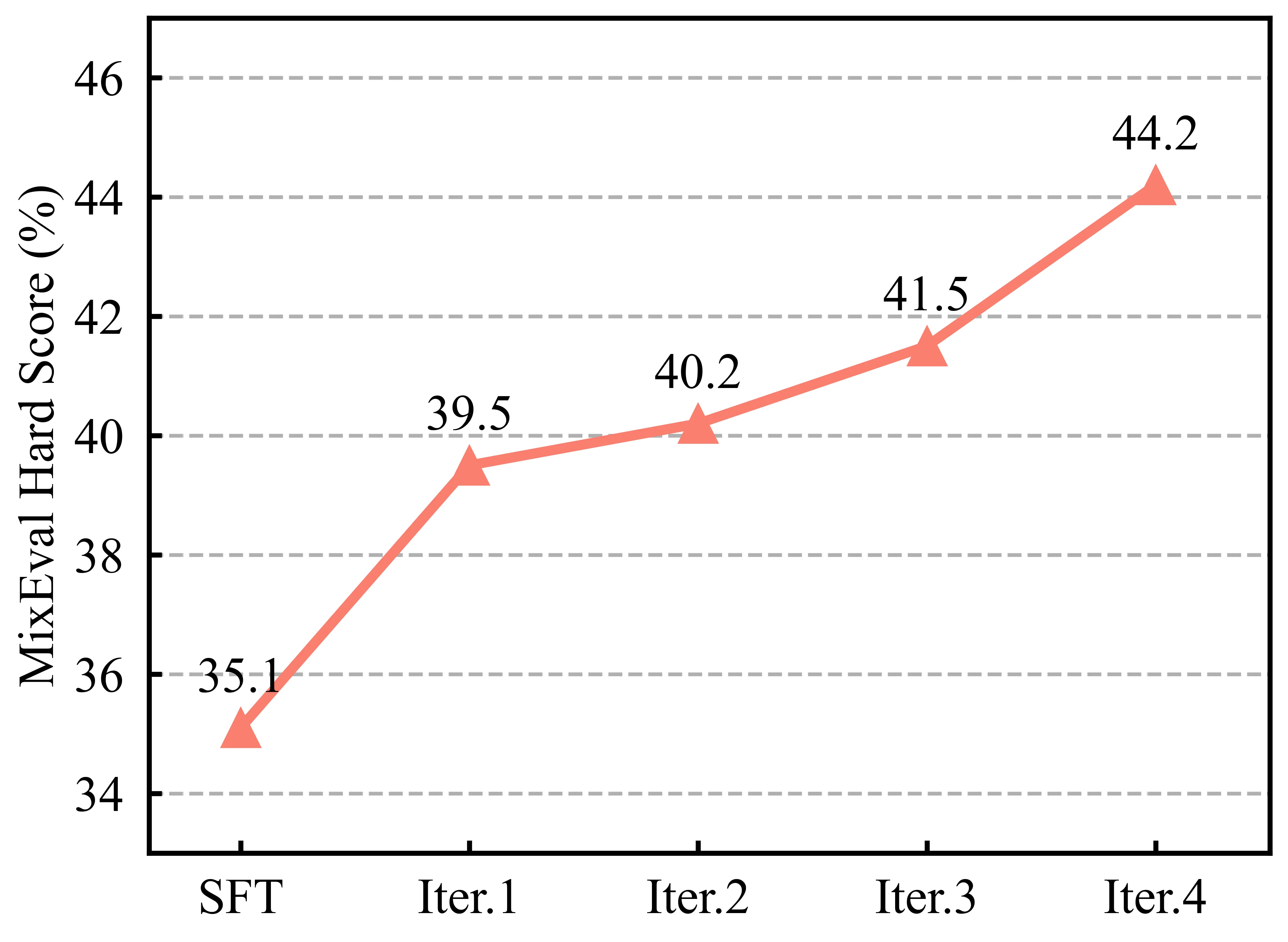
结果显示,MPO 在提升对齐效果的同时,很好地保持了基础能力。在 9 个评测维度中,MPO 在 6 个维度上优于或持平基线,仅在极少数专业任务上略有下降。这种平衡难能可贵,凸显了算法的稳健性。
磁性强度的影响
消融实验揭示了磁性参数 的关键作用。当 时,算法退化为标准迭代 DPO,收敛曲线呈现明显波动,最终性能欠佳。随着 增大,收敛变得更加平滑稳定,模型性能单调提升。
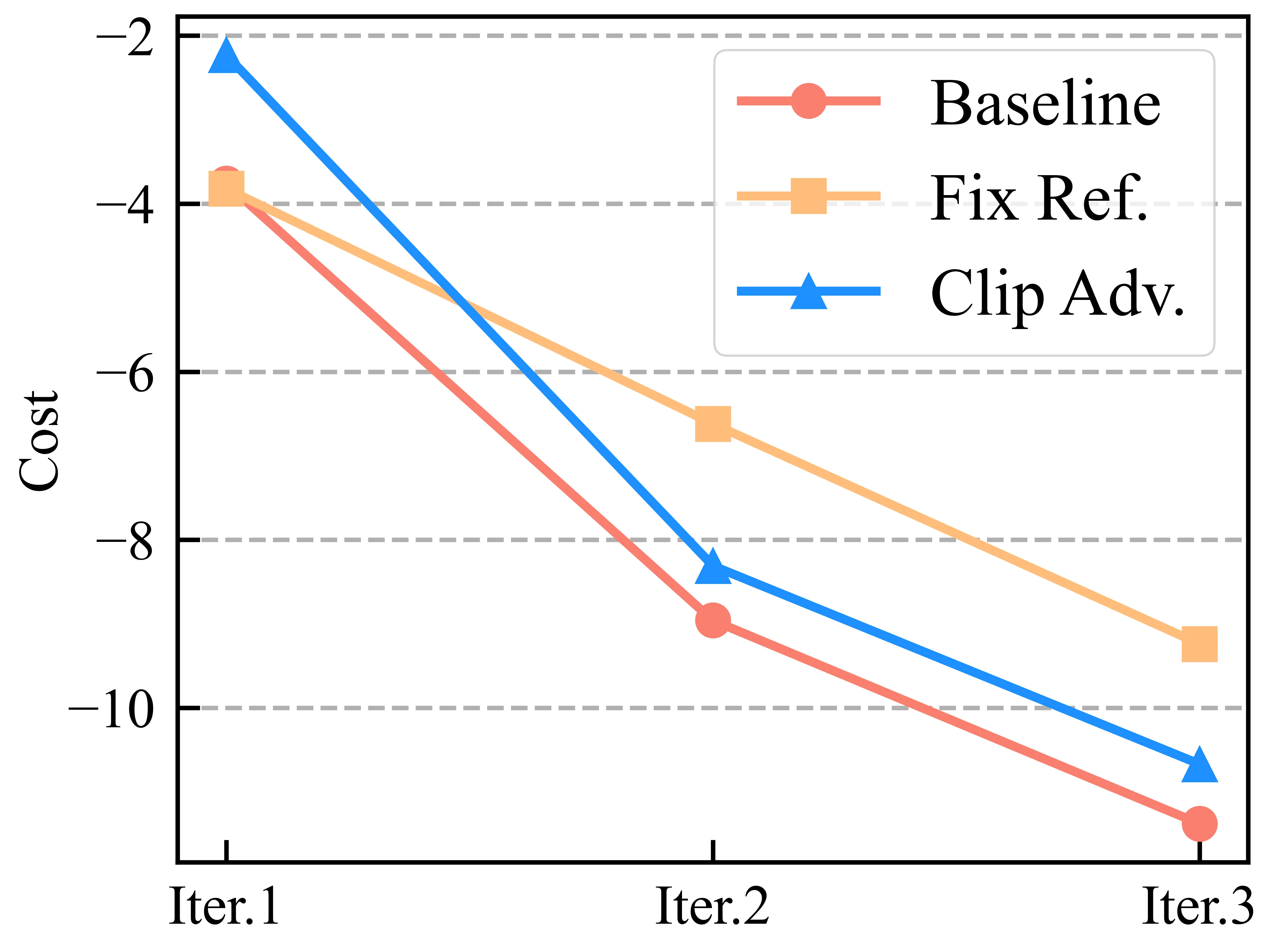
然而 并非越大越好。过大的磁性强度会过度抑制策略更新,减慢收敛速度。实验发现 是较优范围,该区间内算法在收敛速度和最终性能间取得最佳权衡。
6. 自博弈对齐的未来图景
MPO 的成功不仅仅是一个算法的胜利,更揭示了自博弈对齐范式的深层潜力。传统监督微调依赖固定的人类反馈数据集,本质上是模仿学习。而自博弈通过策略间的持续对抗,能够自主探索策略空间,发现监督数据无法覆盖的改进方向。
超越 Bradley-Terry 假设
现有大部分偏好优化方法建立在 Bradley-Terry 模型之上,该模型假设存在潜在的奖励函数,偏好关系可由奖励差异完全决定。然而人类偏好往往是非传递的、上下文依赖的、多维度的,难以用单一标量奖励刻画。
自博弈框架绕开了这一假设。通过直接优化博弈的纳什均衡,算法无需假设偏好的生成机制,能够适应更复杂的偏好结构。MPO 的理论分析表明,即使在非凸、非光滑的偏好函数下,算法仍能稳定收敛。
计算效率的革命
最终迭代收敛的意义远不止理论层面。在工业部署中,模型的存储和推理成本往往是瓶颈。平均迭代方法要求维护数十个检查点,占用数 TB 存储空间,推理时需要集成多个模型的输出,延迟成倍增加。
MPO 彻底消除了这些开销。训练过程只需保存最新模型,部署时也只需加载单一检查点。对于参数量达数百亿的大模型,这种简化节省的资源可观,使得自博弈对齐在实际系统中变得切实可行。
总结与展望
尽管 MPO 取得了显著进展,自博弈对齐仍有广阔探索空间。当前算法假设偏好模型已知且固定,但实际中偏好标注存在噪声和不确定性。如何在不完美反馈下保持收敛性,是重要的开放问题。
多智能体博弈提供了另一条路径。将对齐任务建模为涉及生成、批判、验证等多个角色的复杂博弈,可能解锁新的能力涌现。MPO 的理论框架能否扩展到这类设定,值得深入研究。
对齐与泛化的权衡也需要更细致的理解。过度优化人类偏好可能导致模式崩塌和过拟合。如何在追求对齐的同时保持模型的创造性和鲁棒性,关系到 AI 系统的长期发展。