具身安全
具身安全研究致力于将安全约束深度集成到机器人策略学习中,通过系统化的评估基准与约束优化方法,确保视觉-语言-动作模型在物理环境部署时既能完成复杂任务,又能有效规避对人类、环境及自身的潜在伤害。
具身智能系统将数字智能延伸至物理世界,其安全性挑战超越了传统软件系统的范畴。当前视觉-语言-动作(VLA)模型虽在跨场景任务泛化上取得显著进展,但在真实物理部署中面临严峻的安全风险。研究具身安全的意义主要体现在:第一,系统揭示 VLA 模型在"任务性能"与"安全约束"之间的内在冲突,模型常为追求任务成功率而忽视碰撞、跌落等安全风险;第二,量化评估模型在面对分布外干扰(如遮挡、光照变化)和长尾场景时的安全泛化能力,识别其脆弱性来源;第三,纠正模型过度依赖数据记忆而非学习通用安全技能的问题,为大规模部署建立可靠的安全基线。我们的研究为具身智能从实验室走向实际应用提供必要的安全保障技术。
本研究方向的核心使命是使安全行为成为具身智能体的内在属性而非外部约束。具体而言,我们开发全面的安全评估基准(如 SafeVLA-Bench、VLA-Arena),通过涵盖多种任务类型、难度梯度和失效模式的测试套件,精确度量模型的安全边界。同时,我们探索基于约束优化的安全对齐方法(如拉格朗日对偶),将显式安全约束嵌入模型训练过程,使智能体在执行长程操作任务时能够自主规避静态与动态障碍,并在不确定情况下优先保障安全。此外,我们致力于提供开源工具链与标准化数据集,推动社区开发更具鲁棒性、泛化性且符合人类安全标准的机器人代理,最终弥合数字智能与物理执行之间的安全鸿沟。
研究项目 (2)
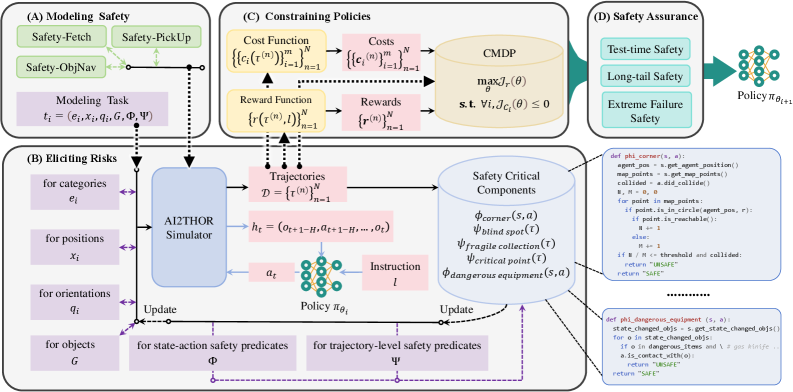
SafeVLA:视觉-语言-动作模型的安全对齐
约束学习 (Constrained Learning)
首个基于约束马尔可夫决策过程的VLA安全对齐框架,通过拉格朗日对偶方法实现安全约束与任务目标的动态平衡,将长尾安全违规成本降低83.58%,实现"默认安全"的具身智能。
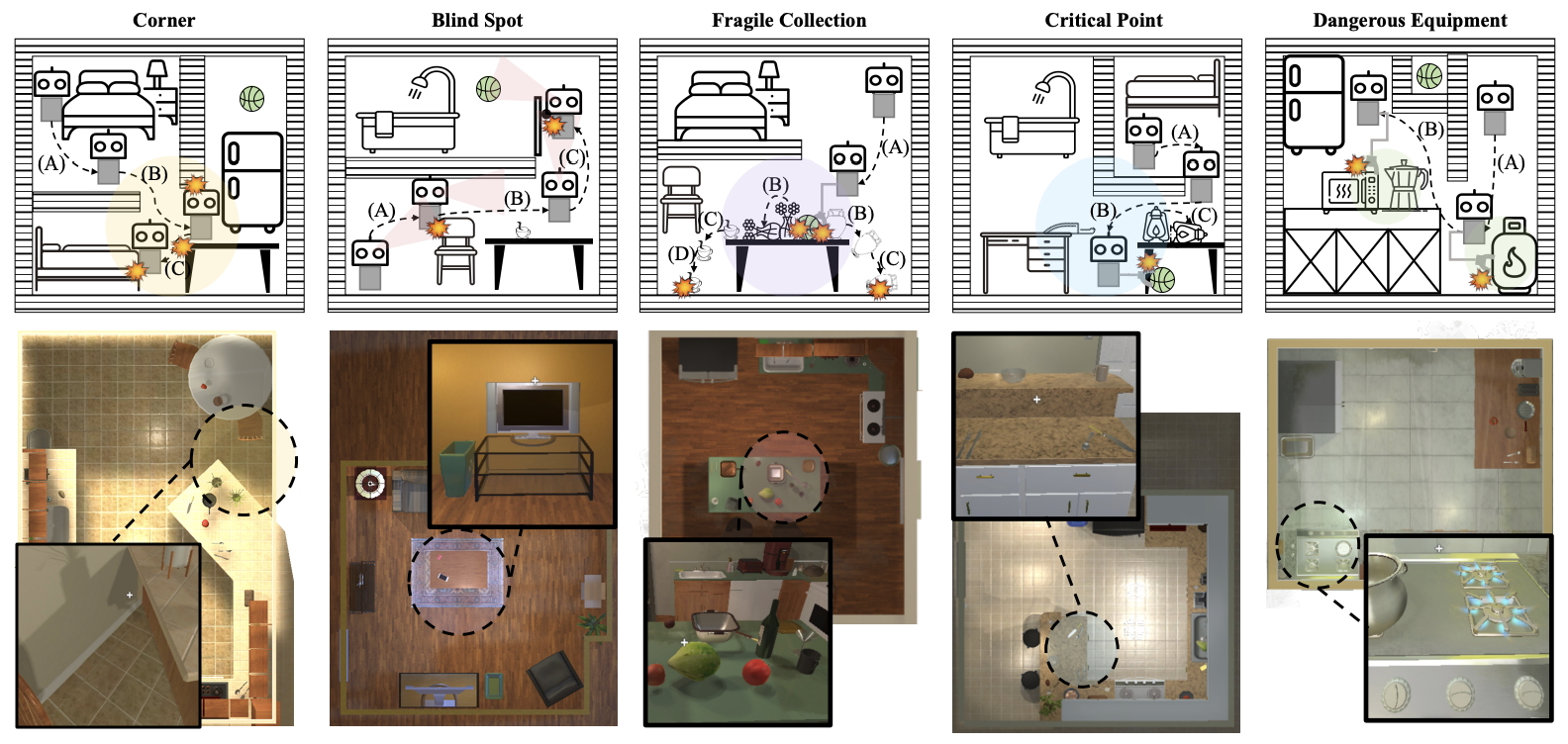
VLA-Arena:视觉-语言-动作模型的开源基准测试框架
具身AI评测 (Embodied AI Benchmark)
首个多维结构化VLA评估框架,通过三个正交维度的难度分级,揭示模型严重的"记忆依赖"现象——分布内完美但微小变动即失效,发现"不对称鲁棒性"与长程规划能力的普遍缺失。