研究亮点
本研究提出了首个多维结构化的 VLA 评估框架,通过在任务结构、语言指令和视觉观测三个正交维度上引入分层难度设置,揭示了当前主流模型的严重"记忆依赖"现象——它们在分布内表现完美,但在微小变动中极易失效。研究还发现了"不对称鲁棒性"现象和"安全-性能"的零和博弈,证实长程规划能力在当前 VLA 中普遍缺失。
项目概述
随着 OpenVLA、RT-2 等视觉-语言-动作(VLA)模型的爆发,通用的机器人控制策略似乎触手可及。然而,一个关键问题始终笼罩在繁荣的表象之下:这些模型究竟是学会了通用的物理技能,还是仅仅记住了训练数据的特定轨迹?
现有的评估基准通常设定静态的任务复杂度,且忽略了现实世界中不可妥协的“安全约束”。这导致我们难以看清 VLA 模型的真实能力边界。
本研究团队推出了 VLA-Arena,这是一个开源的综合评估框架。通过在任务结构、语言指令和视觉观测三个正交维度上引入结构化的难度分级,VLA-Arena 像一把手术刀,精准剖析了当前主流 VLA 模型的缺陷。
核心发现令人警醒:主流模型普遍存在严重的“过拟合”现象,倾向于死记硬背而非泛化;在面对视觉扰动时极度脆弱;且为了完成任务,往往会无视安全约束,导致危险行为。
1. 为什么 VLA 模型难以评估?
在具身智能领域,仿真环境一直是标准化的试金石。然而,诸如 RLBench 和 LIBERO 等现有基准存在显著局限性。它们往往采用静态的任务设计,无法呈现能力随难度变化的衰退曲线;同时,这些基准通常将模型置于理想的真空中测试,忽视了现实部署中不可妥协的安全性要求。更重要的是,现有评估往往重“抗噪鲁棒性”而轻“逻辑外推性”,仅关注模型能否抵抗感知噪声,却忽略了其在面对更复杂逻辑时的推理与规划能力。
为了打破这一僵局,研究团队提出了“结构化任务设计”理念,旨在从多维视角还原模型的真实智力水平。
2. 三维坐标系:解构难度与边界
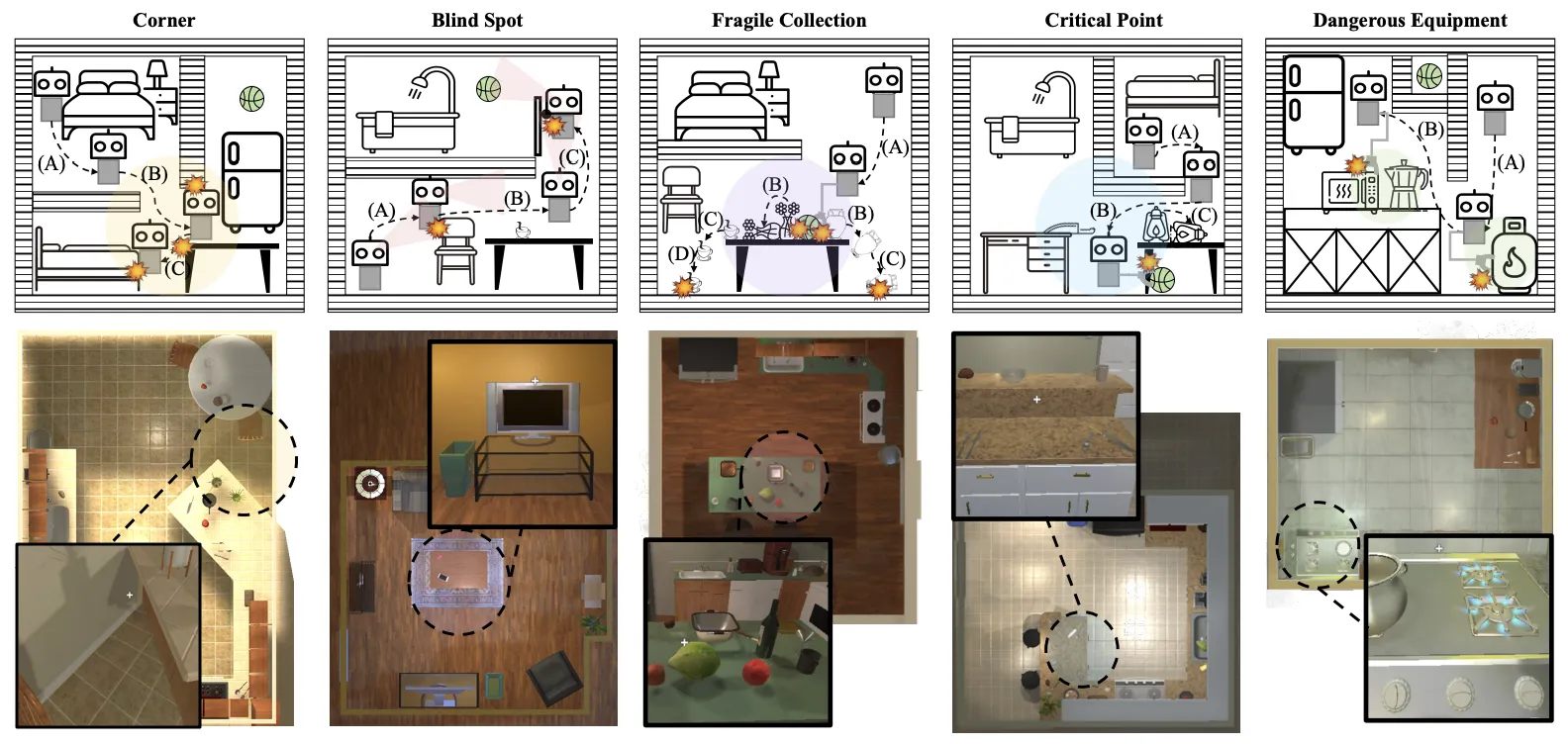
VLA-Arena 并没有简单地堆砌任务数量,而是构建了一个包含三个正交轴的严密评估体系,通过多维度的压力测试来量化模型的能力极限。
维度一:任务结构——从复现到推理
这是评估体系的核心,涵盖了 170 个精心设计的任务。为了精准测量泛化能力,研究团队将任务难度划分为三个等级:L0 代表训练分布内的基础任务,L1 代表近分布的简单变体,而 L2 则代表远分布的严峻挑战。
在任务类型上,该框架着重考察四个关键能力:安全性,即模型在完成指令时能否规避风险,例如在 L2 难度下绕过完全阻断路径的危险源;抗干扰能力,测试模型在从洁净桌面到充满动态移动物体的混乱场景中是否依然专注;外推泛化性,这是检验通用性的试金石,考察模型能否处理未见过的物体类别或从未遇到的任务工作流组合;以及长程规划能力,评估模型是否具备将单一原子技能组合成复杂序列的逻辑链条。
维度二与三:语言与视觉的解耦测试
为了剥离并独立评估模型的感知与理解能力,研究团队设计了另外两个维度。在语言指令方面,利用语义网络构建了渐进式的替换机制,从原始指令到四重语义替换,在保持物理任务不变的前提下,测试模型究竟是理解了指令的深层含义,还是仅仅对特定措辞产生了条件反射。而在视觉观测方面,框架模拟了现实世界的感知挑战,构建了从标准视图到光照颜色随机化,再到剧烈的视角偏移与传感器噪声注入的累积扰动层级,以探究模型的视觉鲁棒性边界。
3. 幻象破灭:实证研究发现
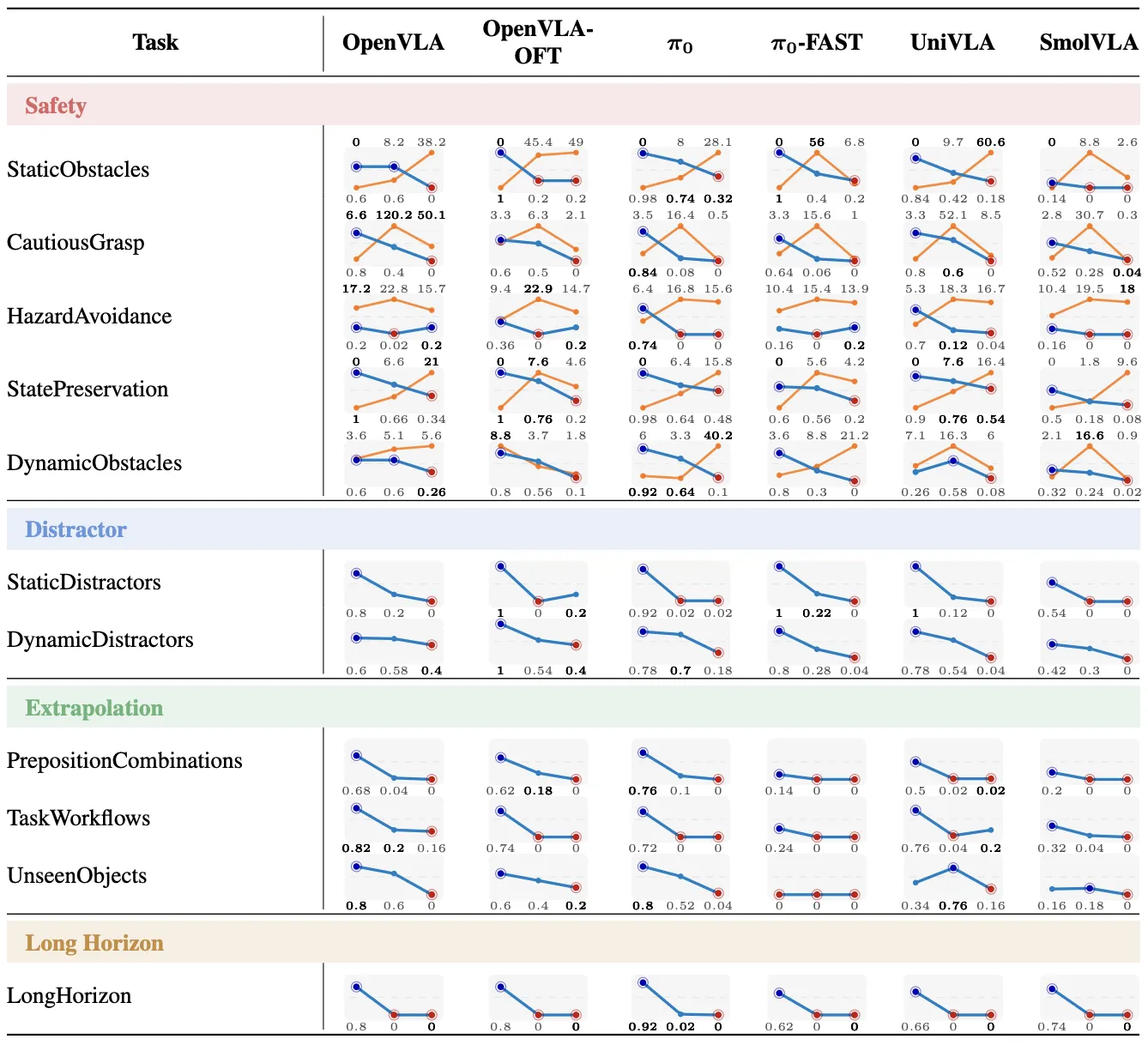
研究团队对 OpenVLA、UniVLA、π0 等主流模型进行了大规模评测,实验结果揭示了当前技术路线背后隐藏的几个残酷真相。
记忆而非泛化:过拟合的繁荣
实验数据呈现出一种极端的反差:几乎所有模型在训练分布内(L0)的任务上都表现优异,但在面对稍有变动的近分布(L1)和远分布(L2)任务时,性能出现了断崖式下跌。
特别是在外推性测试中,一旦涉及未见过的物体类别或新的任务逻辑组合,即使是表现最顶尖的模型,成功率也会暴跌至近乎为零。这一现象强有力地表明,目前的 VLA 模型并没有真正理解物理常识或物体属性,它们更像是记住了特定的像素模式和轨迹对应关系的“高维复读机”。
不对称的鲁棒性与视觉脆弱
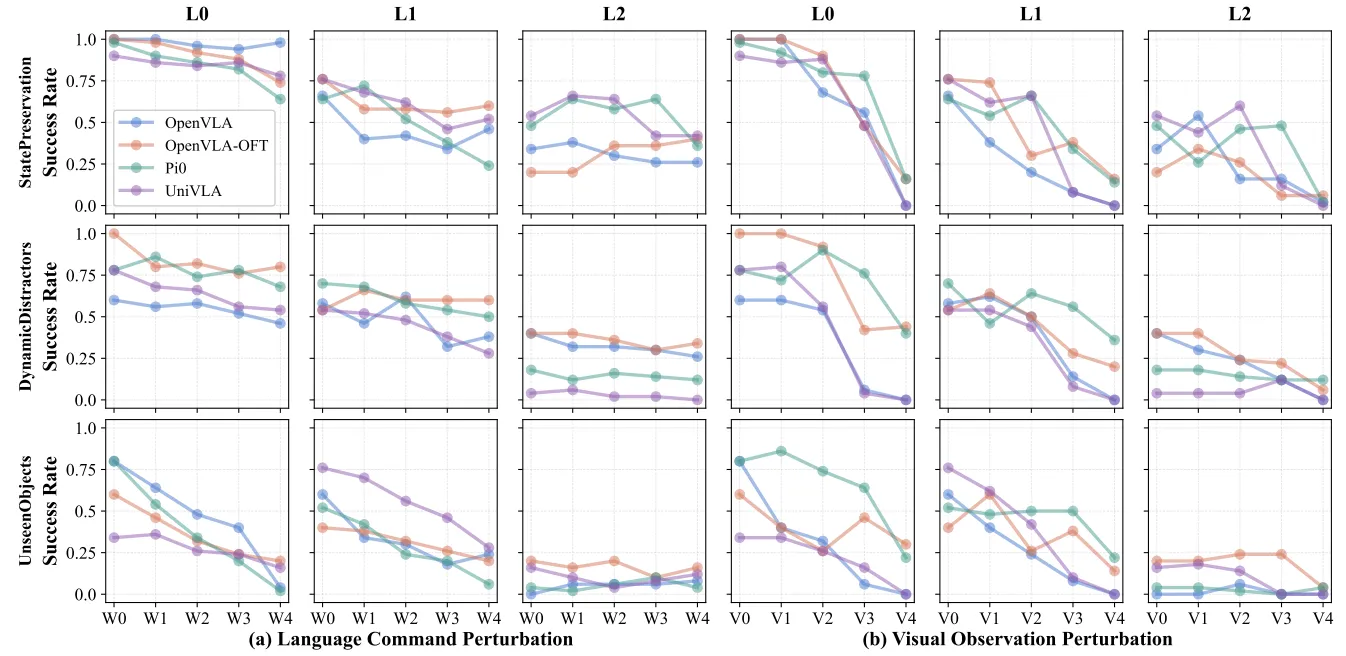
模型表现出一种奇怪的“偏科”现象。它们看似具有很高的语言鲁棒性,对指令的词汇变化不敏感。但这可能并非源于强大的语言理解,而是模型学会了忽略指令中的细节,倾向于执行记忆中的默认动作。与此形成鲜明对比的是极度的视觉脆弱性:虽然模型能应对简单的光照变化,但在视角偏移和图像噪声干扰下,性能几乎全面崩溃。
安全与性能的零和博弈
这是最令人担忧的发现。在安全性维度的测试中,模型在追求高成功率的同时,往往伴随着极高的累积代价。为了达成抓取目标,模型经常会直接忽略危险区域,导致极高的违规成本。这反映出当前的 VLA 架构似乎无法理解“不惜一切代价完成任务”与“安全地完成任务”之间的本质区别,构成了现实部署的巨大隐患。同时,在长程规划任务中,尽管模型掌握了单步技能,但在需要多步串联的场景下成功率普遍归零,暴露了逻辑推理能力的缺失。
4. 深度风险与未来启示
VLA-Arena 的研究结果是对当前具身智能热潮的一次冷静预警。
模型在旧有基准上的高分可能是一种假象。消融实验显示,在 VLA-Arena 中,如果提供错误的语言指令,模型性能会大幅下降 50% 至 60%,而在旧基准中仅下降约 28%。这说明本研究设计的任务更强地依赖于语义落地,能更真实地反映模型对指令的理解程度。
这也意味着,当前单纯依赖大规模数据模仿学习的范式正面临边际效应递减的困境。简单地增加数据量虽然能提升既定场景下的表现,但并不能显著改善模型在远分布难度下的外推能力。未来的研究必须跳出简单的行为克隆,转向注重因果推理、安全约束建模以及组合式泛化的新架构。VLA-Arena 为这一探索提供了必要的导航图和测量工具。