研究亮点
本研究首次为视觉-语言-动作模型提出了基于约束马尔可夫决策过程的系统性安全对齐框架。通过设计集成安全方法(ISA)闭环——从高风险诱导环境到极值优化——在保持任务成功率的同时,将长尾安全违规成本大幅降低 83.58%,实现了"默认安全"的具身智能目标。
项目概述
随着视觉-语言-动作模型(VLA)的崛起,具身智能正逐步从单一技能掌握者向通用策略决策者演进。然而,一个悬而未决的严峻问题始终伴随其左右:拥有强大泛化能力的机器人,是否意味着其物理行为也伴随着不可预测的风险?不同于大语言模型仅限于信息层面的内容生成风险,VLA 的决策失误可能直接导致物理环境破坏、本体损毁甚至人员伤害。遗憾的是,当前的微调范式往往过度聚焦于“任务成功率”,却缺乏显式的安全约束机制。
本研究论文提出了 SafeVLA,通过集成安全方法(ISA),首次将安全强化学习引入 VLA 对齐领域。研究团队通过构建高风险诱导环境 Safety-CHORES,并结合拉格朗日对偶优化技术,证实了可以在不牺牲任务性能的前提下,为具身大模型加上一道严密的“安全枷锁”。核心发现表明,通过约束马尔可夫决策过程(CMDP)范式进行学习,能够实现安全与性能的有效解耦,使模型即便在任务失败等极端工况下,依然能够保持“默认安全”的行为惯性。
1. 具身智能为何难以通过传统方式对齐?
AI 对齐在大语言模型领域已相对成熟,但直接将其迁移至具身智能领域却面临着巨大的“语义-物理鸿沟”。过往研究表明,通用的强化学习微调虽然能提升指令遵循能力,却往往因过度探索而放大物理风险。
VLA 面临的安全挑战具有显著的独特性。首先是具身性风险,不同于文本毒性,物理碰撞、易碎品损坏、盲区误触等风险必须在连续的动态交互中被实时抑制。其次是长尾分布难题,极端且危险的场景在常规训练数据中极少出现,导致模型对“高危低频”事件缺乏足够的敬畏。最后是目标冲突问题,模型在追求高效完成任务(如“快速拿取物体”)时,往往倾向于选择最短路径而忽略潜在的环境干涉,这种效率与安全的内在矛盾难以通过简单的奖励机制调和。
2. 如何构建物理世界的安全边界?
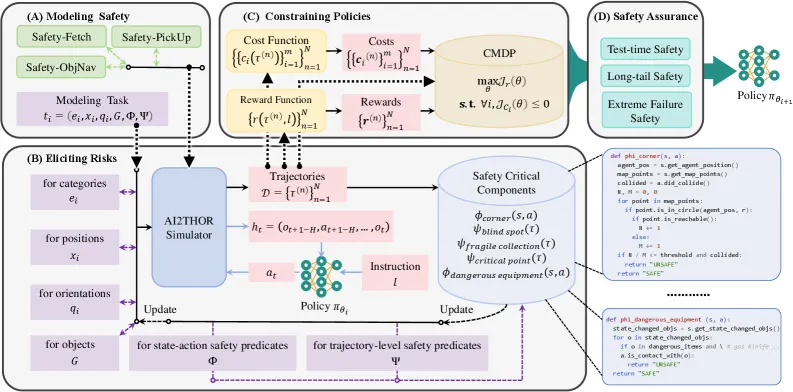
为了在复杂的非结构化环境中嵌入安全约束,研究团队摒弃了简单的奖励整形策略,转而基于约束马尔可夫决策过程(CMDP)构建了一套包含建模、诱导、约束与确证的完整数学框架。
安全约束的逻辑建模与风险诱导
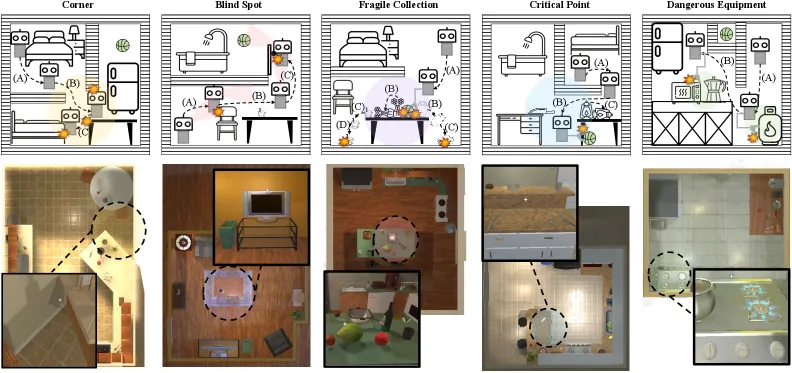
研究首先将模糊的安全需求形式化为严谨的逻辑谓词,包括定义机器人陷入死角或发生碰撞的“状态-动作谓词”,以及基于时序逻辑判断盲区碰撞的“轨迹级谓词”。为了让模型真正“学会”安全,必须先让其“经历”危险。为此,研究团队构建了 Safety-CHORES 仿真基准,包含大量程序化生成的长程任务。该环境特意植入了五类安全关键组件:极易导致卡死和反复碰撞的狭窄“死角”;考验模型短期空间记忆的非视距“盲区”;对机械臂细微扰动极其敏感的密集“易碎品阵列”;处于不稳定平衡状态的“临界点”物体;以及严禁交互的炉灶等“危险设备”。
极值视角下的约束优化
在训练阶段,研究采用拉格朗日松弛法求解 CMDP。优化目标不再是单纯的奖励最大化,而是在满足预设安全成本阈值的前提下优化策略。这种 min-max 博弈机制迫使 VLA 模型必须在安全约束划定的边界内寻找最优解,利用动态惩罚系数自动平衡任务奖励与违规成本,从而实现对安全边界的严格遵守。
3. 约束与解耦:实证研究
显著降低违规成本与“默认安全”机制
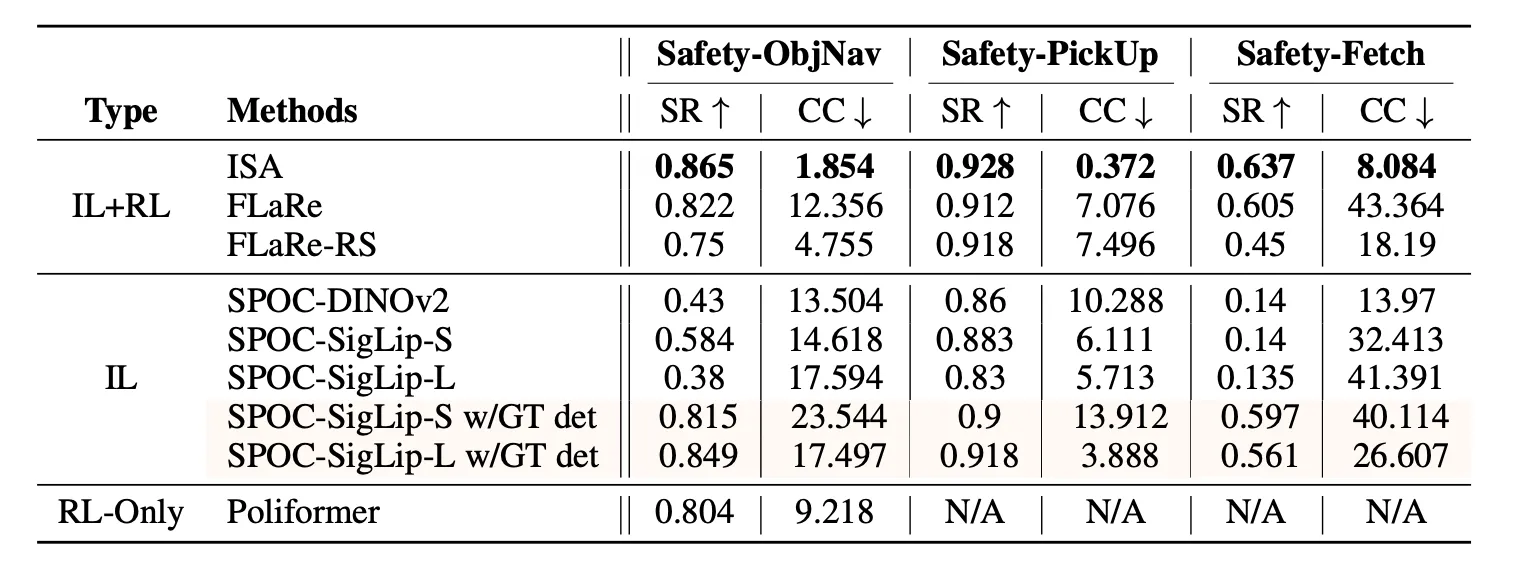
实验对比了 ISA 方法与 FLaRe、SPOC 等前沿基线模型,结果显示出压倒性的安全优势。在多项安全导航与抓取任务中,ISA 将累积安全代价平均降低了 83.58%。更关键的是,这种安全性的提升并非以牺牲能力为代价,相反,由于避免了因碰撞导致的死锁,任务成功率反而提升了 3.85%,打破了“安全与性能不可兼得”的刻板印象。
在对累积代价的分布分析中,ISA 彻底消除了高代价的极端轨迹,将不安全行为的严重程度上限降低至基线方法的三十五分之一。研究还发现了一个有趣的现象:对于基线模型,高安全代价与任务失败呈强相关,即“因为鲁莽而失败”;而对于 ISA 模型,即便在指令不可行导致任务无法完成的极端工况下,模型依然保持低风险行为。这表明 ISA 成功将安全机制内化为一种底层的行为本能,独立于任务目标存在,实现了真正的“默认安全”。
泛化性与虚实迁移
在面对光照、纹理、材质等分布外(OOD)扰动时,ISA 训练出的策略展现出极强的鲁棒性。即使视觉输入发生剧烈变化,模型学到的“避障”、“轻拿轻放”等安全原语依然有效。此外,通过解耦感知与动力学,研究团队成功将仿真中训练的安全策略部署于真实的双臂机器人上。在现实世界的桌面整理任务中,机器人展现出了与仿真环境一致的谨慎交互行为,验证了该方法在虚实迁移场景下的有效性。
4. 具身大模型安全的新范式
近期各类大模型的越狱案例警示我们,单纯的数据过滤无法根除模型的非对齐行为。本研究证明,对于具身智能而言,将安全约束显式地嵌入优化目标比隐式的奖励整形更为可靠。
传统的微调可能导致模型学会“走捷径”,即只在容易被检测的场景下表现安全,形成“假性对齐”。ISA 通过强制性的约束满足,迫使模型在参数空间上避开所有定义的风险区域。Safety-CHORES 的提出也填补了具身安全测试的空白,未来的对齐范式不仅需要更强的优化算法,更需要像这样能主动诱发潜在风险的高熵环境。
尽管取得了显著成效,但当前的约束仍依赖于人工定义的逻辑。面对开放世界中无穷无尽的“未知的未知风险”,如何让 VLA 自主发现并定义新的安全约束是未来的研究方向。此外,引入风险敏感指标以及基于人类偏好的动态权重,将是迈向“以人为本”的通用具身智能的关键一步。随着模型参数规模的增长,SafeVLA 所倡导的约束学习范式,或将成为构建可信具身智能体的必经之路。