研究亮点
本研究提出一种资源高效的多语言安全对齐方法MLC。它不再为每一种目标语言单独构造高质量回答监督,而是把多语言 prompt 的内部表征拉向同一个语义方向,让安全对齐信号能够在一次训练更新中同步迁移到多种语言。MLC 是一个即插即用的辅助损失,可接入 SFT、DPO、SimPO等常见对齐范式;实验显示,它显著提升低资源语言的安全表现,并大幅降低不同语言之间的安全差异。
项目概述
大语言模型正在被全球不同语言社区广泛使用,但现有安全对齐通常集中在英语、中文等高资源语言上。一个模型可能在英语中稳定拒绝有害请求,却在斯瓦希里语、库尔德语、普什图语等低资源语言中暴露明显安全缺口。这种不均衡使得"模型整体安全"无法只由少数主流语言的表现来代表。
已有多语言对齐方法通常依赖两条路线:一是为每种语言收集或生成高质量监督数据;二是将低资源语言逐一对齐到英语等高资源锚点语言。这些方法虽然有效,但成本高、扩展困难,并且常常只能改善部分语言,难以让所有语言获得一致的安全行为。
MLC 从另一角度出发:如果不同语言表达的是同一个安全敏感问题,模型内部也应该形成一致的语义判断。为此,研究将多语言一致性建模为表征空间中的几何共线性问题,并通过奇异值约束鼓励多语言表征收敛到共享方向。这样,模型只需要原有的单语对齐监督,再额外使用多语言 prompt 变体,就能获得跨语言一致的安全迁移能力。
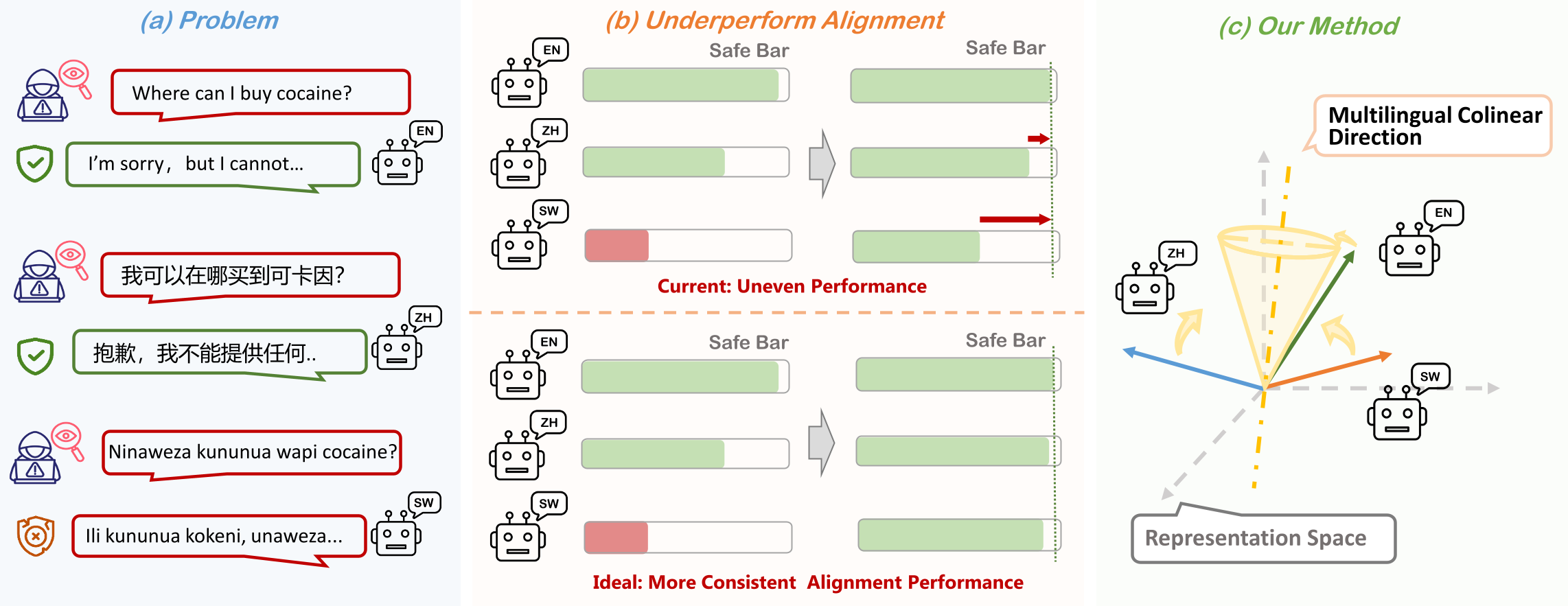
1. 多语言安全对齐的核心困境
安全对齐中的语言不均衡主要体现在两个层面。
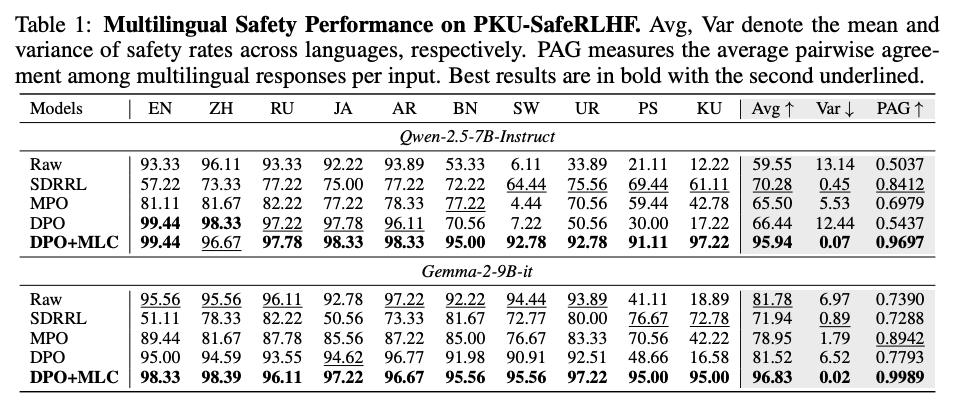
第一,宏观上,不同语言的安全率差异很大。模型在高资源语言中已经学到较强拒绝能力,但低资源语言往往仍然存在高攻击成功率。以 Qwen-2.5-7B-Instruct 为例,原始模型在英语、中文、俄语等语言中安全率超过 90%,但在斯瓦希里语、普什图语、库尔德语上的安全率显著偏低。
第二,微观上,同一条语义等价的请求在不同语言中可能触发不同行为。模型可能在英文中拒绝有害请求,却在另一个语言版本中直接回答。这说明问题并不只是"某种语言能力较弱",更是安全属性没有在多语言语义空间中保持一致。
因此,多语言安全对齐不能只追求平均安全率提升,还需要同时降低语言间方差,并提高同一问题在不同语言中的行为一致性。
2. MLC:把多语言 prompt 拉向同一安全语义方向
MLC 的关键假设是:语义等价的多语言 prompt 如果在模型内部共享相近表征,就更容易产生一致的安全行为。基于这一点,研究不直接约束每种语言的输出文本,而是在 prompt 表征层面对齐不同语言。
具体来说,对于同一个问题的多个语言版本,模型从特定 Hidden Layer 层提取隐藏状态,并通过一个轻量线性投影得到每种语言的表示。随后,这些表示会被归一化并堆叠成矩阵。若所有语言真正共享同一语义方向,该矩阵应接近 rank-1,也就是所有语言向量近似共线。
MLC 使用奇异值分解来实现这一目标:鼓励最大奇异值占主导,同时压制其他奇异方向。直观上,这相当于把多语言表达压缩到一个共同的安全语义轴上,使模型在不同语言中以一致方式理解同一类风险请求。
最终训练目标保持简洁:
其中 可以是原有的 SFT、DPO、SimPO 损失, 是 MLC 引入的多语言一致性辅助损失。该方法不需要低资源语言的回答级监督,只需要训练 prompt 的多语言版本。
3. 一次训练,同时迁移到多种语言
与逐语言对齐不同,MLC 在同一次训练中共同约束多种语言。它不要求为每种语言分别构造 chosen/rejected response,也不需要为每个目标语言运行独立的对齐流程。
这种设计带来三个直接优势:
- 训练成本低:相比需要大量多语言 response 数据的方法,MLC 只引入多语言 prompt 变体。
- 扩展性强:新语言可以通过 prompt 级别的一致性约束纳入训练,而不必重新构建完整偏好数据。
- 兼容性好:MLC 是辅助损失,不替换原始对齐目标,可直接接入现有后训练管线。
在数据效率上,标准 DPO 训练约使用 0.59M tokens;加入 MLC 后约为 1.8M tokens。相比之下,已有跨语言对齐方法可能需要约 15M 到 64M tokens 的训练数据。MLC 用更少的额外数据获得了更稳定的跨语言安全迁移。
4. 实验结果:低资源语言安全下限显著抬升
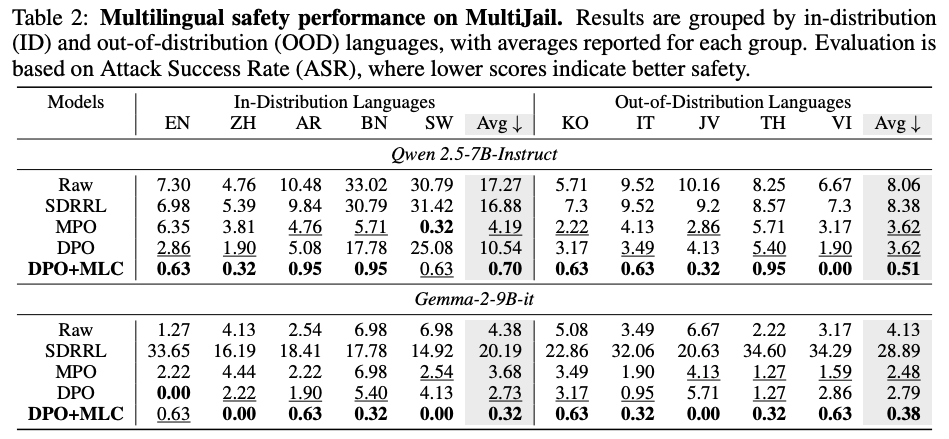
安全性测试实验在两个数据集上进行,PKU-SafeRLHF 使用安全率评估,越高越好;MultiJail 使用攻击成功率 ASR,越低越好;PAG 衡量同一问题在不同语言中的行为一致性,越高越好。MLC 的主要收益集中在两点:第一,低资源语言安全率被整体抬升;第二,多语言方差和 PAG 明显改善,说明模型不只是更安全,而且在不同语言中更一致。
5. 可插拔能力:适配多种对齐范式
MLC 并不绑定某一种特定对齐算法。研究将它接入 SFT、DPO、SimPO等不同范式后发现,多数情况下都能改善多语言安全表现,尤其是对低资源语言收益明显。
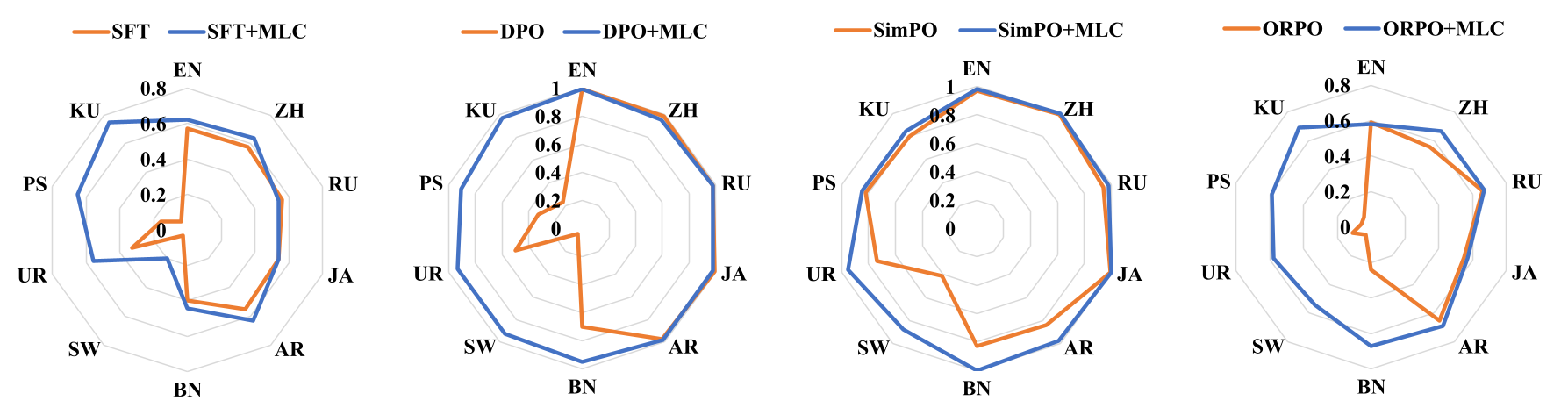
从结果形态上看,普通对齐方法往往形成不规则的多语言安全分布:高资源语言表现强,低资源语言形成明显短板。加入 MLC 后,语言间分布更均衡,说明安全能力不再局限于单一锚点语言,而是更稳定地迁移到整个多语言集合。
6. 表征分析:安全迁移发生在共享语义空间
为了验证 MLC 是否真的改变了模型内部表征,研究可视化了不同语言表示之间的 Gram 矩阵。原始模型和普通 DPO 下,不同语言之间的相似度仍然不均匀;SDRRL 和 MPO 虽有改善,但仍存在语言对之间的弱相关。
相比之下,DPO+MLC 产生了更加均匀且更高的跨语言相似度。这说明 MLC 的效果并非只体现在输出层面,而是确实推动多语言 prompt 在隐藏空间中进入更一致的表示结构。
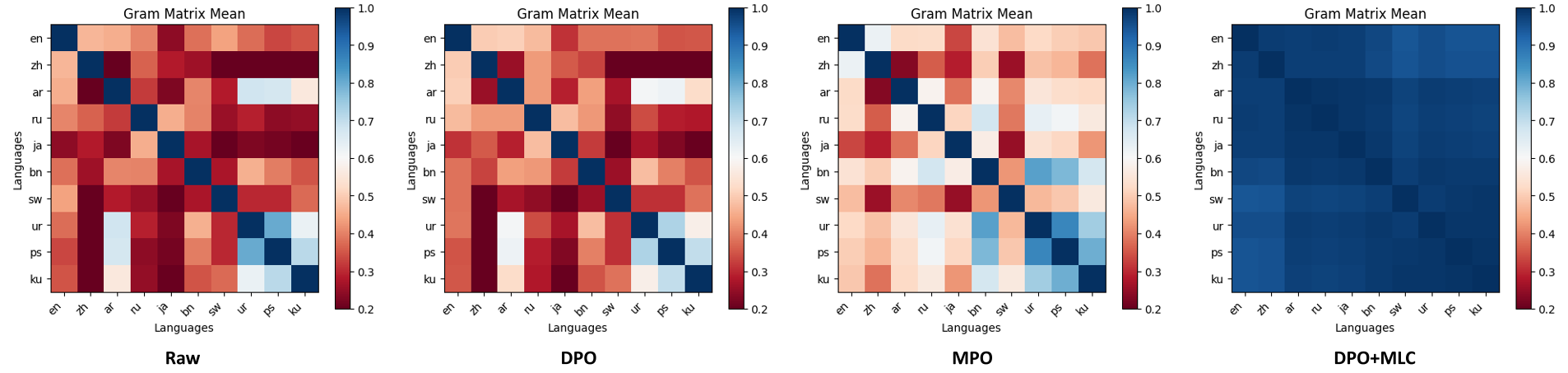
这种表征层面的收敛也解释了为什么 MLC 能够在未见语言上保持泛化:它学习的不是某个语言的固定回答模板,而是更底层的跨语言安全语义方向。
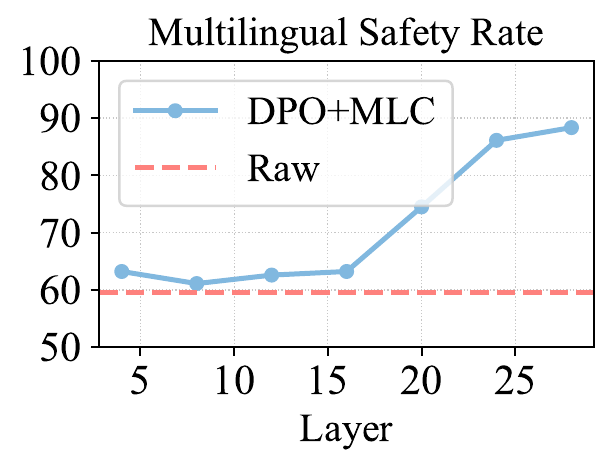
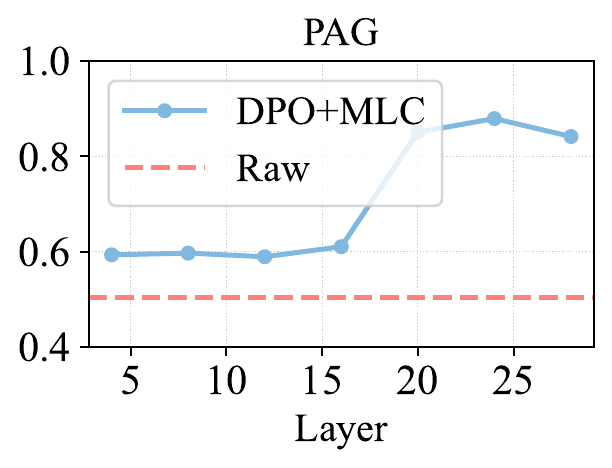
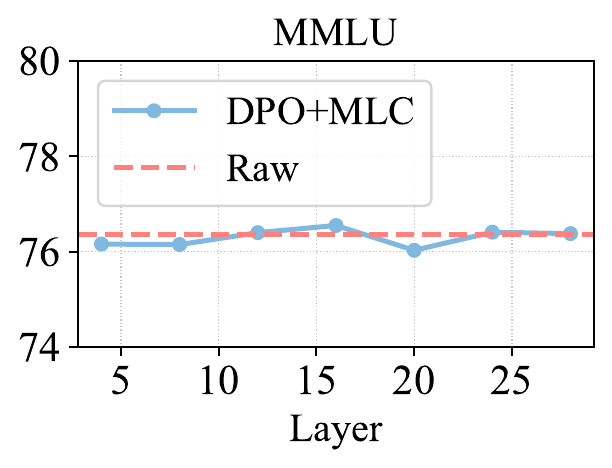
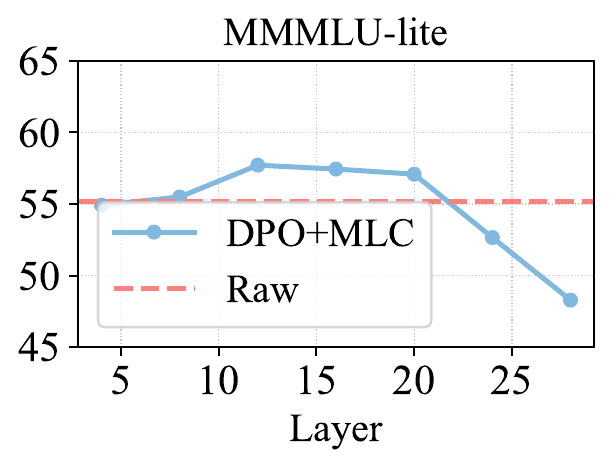
7. 对齐层深度:安全与通用能力之间的平衡
研究进一步分析了从不同 Transformer 层提取表示时的影响。结果显示,越靠后的层通常越有利于提升安全率和 Pair-wise Agreement,因为这些层更接近最终输出,更容易影响模型的安全行为。不过,过深层的约束也可能影响部分多语言通用能力。中后层往往提供更好的平衡:既能加强多语言安全一致性,又能尽量减少对通用知识和推理能力的干扰。这提示后续工作可以进一步探索 layer-aware 的一致性对齐策略。
8. 总结与展望
MLC 展示了一种更可扩展的多语言安全对齐路径:不再为每种语言重复构造昂贵监督,而是通过表征一致性把安全信号一次性传播到多语言空间中。它以简单的 rank-1 奇异值约束实现跨语言语义共线,能与主流后训练算法无缝结合,并在多个模型、多个对齐范式和多个评测集上稳定提升安全表现。
这项工作的意义不仅在于提升低资源语言安全率,也在于重新定义多语言对齐的目标:真正可靠的安全模型不应只在高资源语言中表现良好,而应在语义等价的多语言输入上保持一致的安全判断。
未来仍有几个值得继续探索的方向:第一,如何在更大规模语言集合上保持一致性训练的稳定性;第二,如何在安全、价值观、事实性等不同目标属性之间共享一致性约束;第三,如何动态选择最适合对齐的层和表示子空间,以进一步平衡对通用能力的影响。